Việc hiểu rõ sự khác biệt giữa action và transformation trong Spark là rất quan trọng để viết code Spark hiệu quả và tối ưu hóa các ứng dụng Spark….
Giới thiệu
Giới thiệu về RDD - Resilient Distributed Datasets
RDD, hay Resilient Distributed Datasets, là một cấu trúc dữ liệu cơ bản của Spark. Đây là một tập hợp phân tán bất biến của các đối tượng. Mỗi tập dữ liệu trong RDD được chia thành các phân vùng logic, có thể được tính toán trên các nút khác nhau của cụm. RDDs có thể chứa bất kỳ loại đối tượng Python, Java, hoặc Scala nào, bao gồm cả các lớp do người dùng định nghĩa.
RDDs hỗ trợ hai loại hoạt động: transformation, tạo ra một tập dữ liệu mới từ một tập dữ liệu hiện có, và action trả về một giá trị cho chương trình điều khiển sau khi chạy một tính toán trên tập dữ liệu. Ví dụ, map là một biến đổi mà truyền từng phần tử tập dữ liệu qua một hàm và trả về một RDD mới đại diện cho kết quả. Ngược lại, reduce là một hành động tổng hợp tất cả các phần tử của RDD bằng một số hàm và trả về kết quả cuối cùng cho chương trình điều khiển.
Tất cả các biến đổi trong Spark đều là lazy, nghĩa chúng không tính toán kết quả ngay lập tức. Thay vào đó, chúng chỉ nhớ các biến đổi (mình gọi là các phép transformation) được áp dụng trên tập dữ liệu cơ sở. Các biến đổi chỉ được tính toán khi một hành động (action) yêu cầu một kết quả được trả về cho chương trình điều khiển.
Thiết kế này cho phép Spark chạy hiệu quả hơn. Ví dụ, chúng ta có thể nhận ra rằng một tập dữ liệu được tạo thông qua map sẽ được sử dụng trong một reduce và chỉ trả về kết quả của reduce cho chương trình điều khiển, thay vì tập dữ liệu map lớn hơn.
Dưới đây là một ví dụ về cách tạo một RDD từ một tệp văn bản:
val sc = new SparkContext("local", "First Spark App")
val data = sc.textFile("data.txt")
Hiểu rõ được cơ chế và cách thức hoạt động của action và transformation sẽ giúp chúng ta thiết kế các luồng ETL hiệu quả, tiết kiệm tài nguyên tính toán, và thời gian.
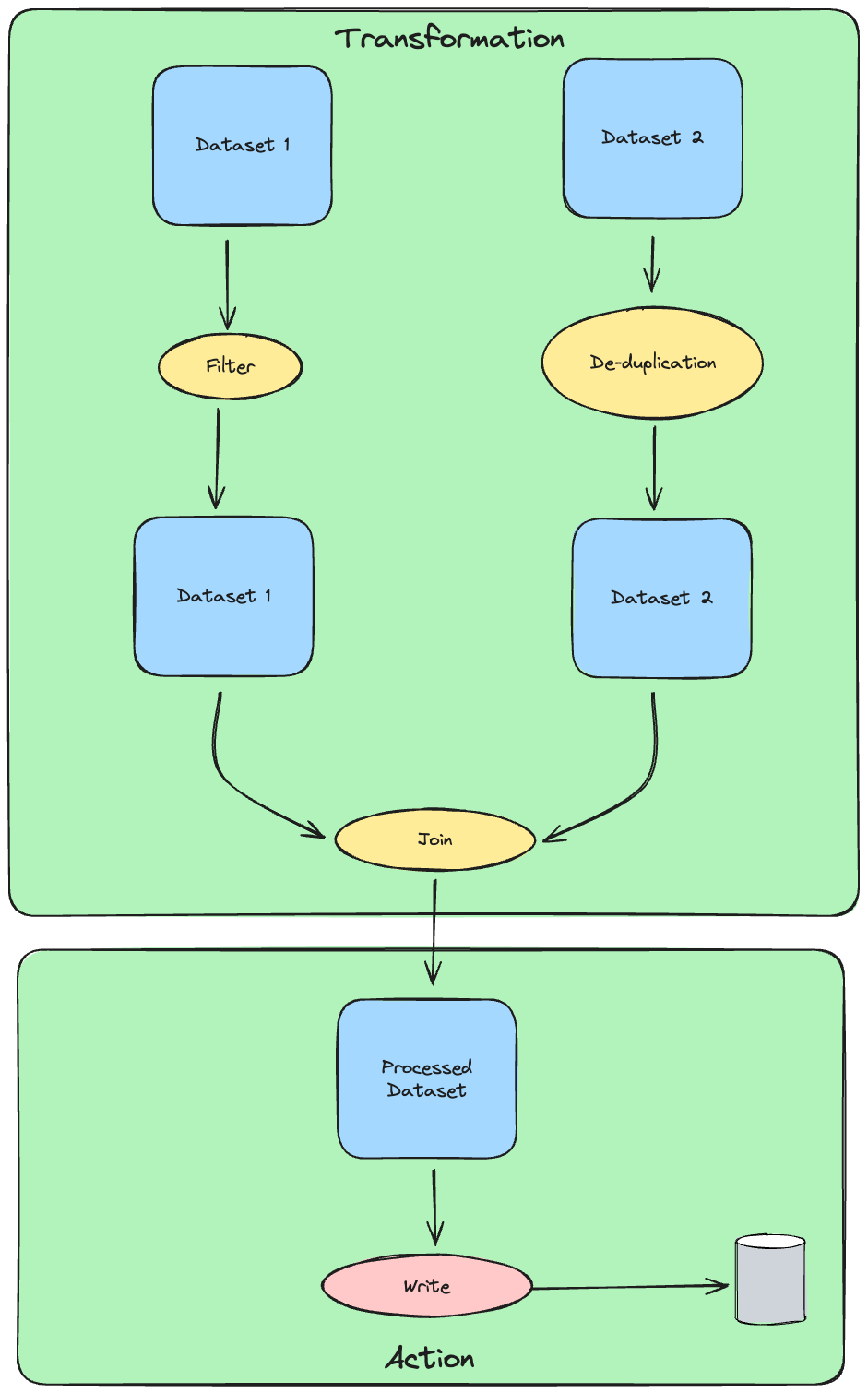
Action và Transformation là gì?
Transformation
Transformation trong Spark là các hoạt động trên RDD (Resilient Distributed Datasets) hoặc DataFrame mà không trả về một giá trị cho chương trình điều khiển. Thay vào đó, chúng tạo ra một RDD mới từ một RDD hiện có. Các Transformation thường được sử dụng khi bạn cần thực hiện một số tính toán trên dữ liệu và sau đó lưu kết quả vào một RDD mới.
Có hai loại Transformation chính trong Spark:
-
Transformation để tạo một RDD mới từ một RDD hiện có: Các hàm như
map(),filter(), vàflatMap()được sử dụng để tạo một RDD mới từ một RDD hiện có. Hàmmap()áp dụng một hàm cho mỗi phần tử của RDD và trả về một RDD mới chứa kết quả. Hàmfilter()trả về một RDD mới chứa chỉ những phần tử của RDD hiện có mà thoả mãn một điều kiện nào đó. HàmflatMap()giống như hàmmap(), nhưng nó “làm phẳng” kết quả bằng cách kết hợp tất cả các phần tử từ tất cả các danh sách thành một danh sách duy nhất. -
Transformation để kết hợp hai RDD: Các hàm như
union(),intersection(),subtract(), vàcartesian()được sử dụng để kết hợp hai RDD. Hàmunion()trả về một RDD mới chứa tất cả các phần tử từ cả hai RDD. Hàmintersection()trả về một RDD mới chứa chỉ những phần tử mà xuất hiện trong cả hai RDD. Hàmsubtract()trả về một RDD mới chứa những phần tử của RDD này mà không xuất hiện trong RDD khác. Hàmcartesian()trả về một RDD mới chứa tất cả các cặp phần tử có thể từ hai RDD.
Đây chỉ là một số hàm khi chúng ta muốn biến đổi trên tập dữ liệu đầu vào. Ngoài ra Spark còn hỗ trợ rất nhiều hàm liên quan đến
SQL, các bạn có thể tham khảo tại đây
Tất cả các Transformation trong Spark đều là lazy, nghĩa là chúng không được thực hiện ngay lập tức khi chúng được gọi. Trong Spark đây được gọi là cơ chế Planning và Analysis, nghĩa là Spark sẽ tạo ra một DAG chứa thông tin một chuỗi các thao tác cần làm trên tập dữ liệu đầu vào nhằm tối ưu hoá các câu lệnh chạy. Chúng chỉ được thực hiện khi một Action yêu cầu một kết quả được trả về cho chương trình điều khiển.
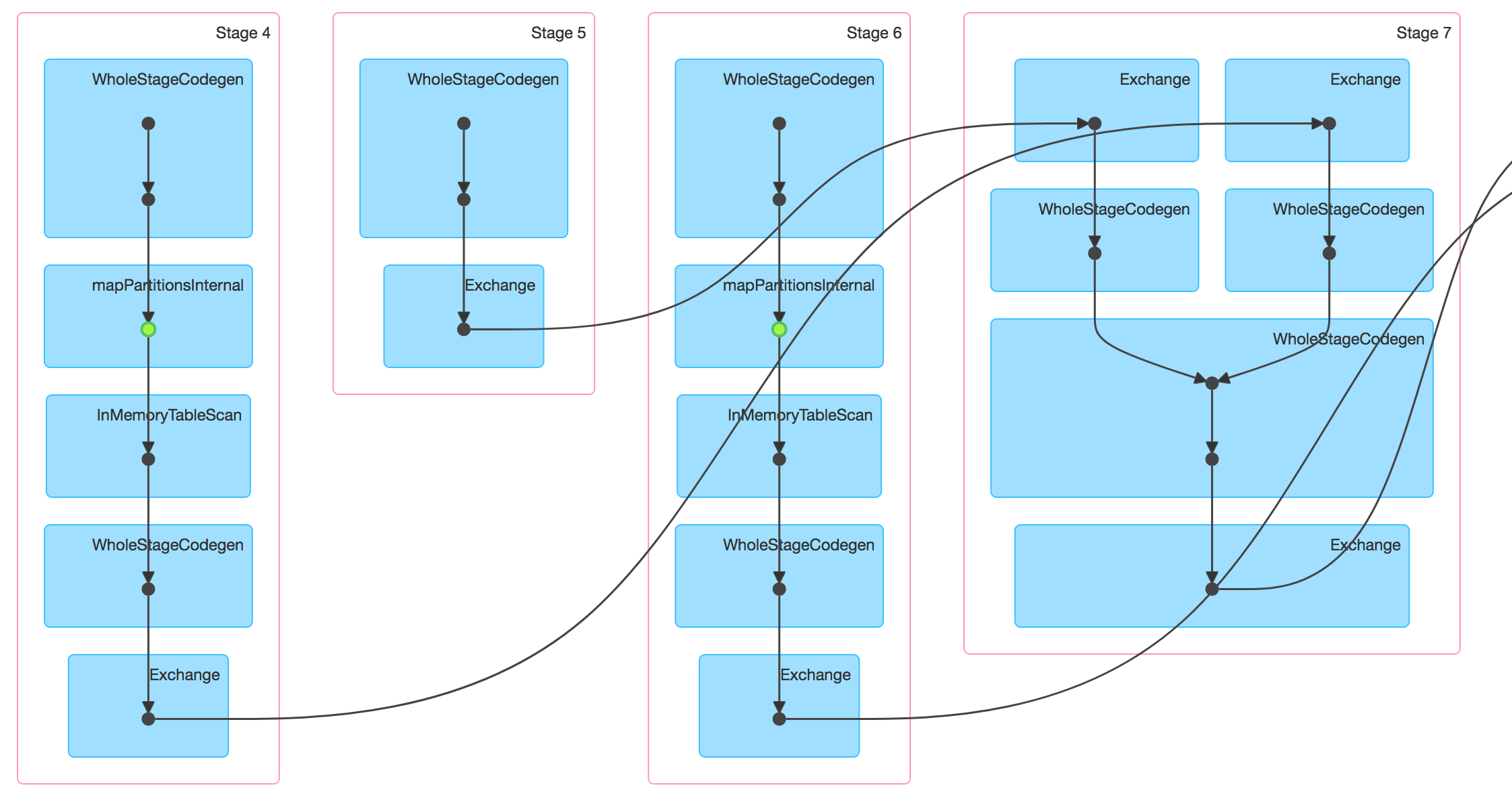
DAG trong spark là gì? (thông tin thêm) DAG, hay Directed Acyclic Graph, là một cấu trúc dữ liệu mà Spark sử dụng để theo dõi các phụ thuộc giữa các hoạt động trong chương trình của bạn. Mỗi nút trong DAG biểu diễn một tập dữ liệu, và mỗi cạnh biểu diễn một hoạt động được áp dụng lên tập dữ liệu. DAG giúp Spark tối ưu hóa việc thực hiện các hoạt động bằng cách cho phép nó xác định được thứ tự tối ưu để thực hiện các hoạt động, và nó cũng cho phép Spark phục hồi nhanh chóng từ các lỗi bằng cách biết được những hoạt động nào cần được thực hiện lại.
Đây là một ví dụ của DAG khi Spark thực hiện Planning các tác vụ cần thực hiện:
from pyspark import SparkContext
sc = SparkContext("local", "First Spark App")
# Example of filter function
rdd = sc.parallelize([1, 2, 3, 4, 5])
filterResult = rdd.filter(lambda x: x % 2 == 0)
print(filterResult.collect()) # Output: [2, 4]
# Example of flatMap function
rdd2 = sc.parallelize(["Hello world", "I am learning Spark"])
flatMapResult = rdd2.flatMap(lambda x: x.split(" "))
print(flatMapResult.collect()) # Output: ["Hello", "world", "I", "am", "learning", "Spark"]
# Example of union function
rdd3 = sc.parallelize([6, 7, 8, 9, 10])
unionResult = rdd.union(rdd3)
print(unionResult.collect()) # Output: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Example of intersection function
intersectionResult = rdd.intersection(rdd3)
print(intersectionResult.collect()) # Output: []
# Example of subtract function
subtractResult = rdd.subtract(rdd3)
print(subtractResult.collect()) # Output: [1, 2, 3, 4, 5]
# Example of join function
rdd4 = sc.parallelize([(1, "one"), (2, "two"), (3, "three")])
rdd5 = sc.parallelize([(1, "uno"), (2, "dos")])
joinResult = rdd4.join(rdd5)
print(joinResult.collect()) # Output: [(1, ("one", "uno")), (2, ("two", "dos"))]
Action
Action trong Spark là các hoạt động trên RDD (Resilient Distributed Datasets) hoặc DataFrame mà trả về một giá trị cho chương trình điều khiển. Khác với Transformation, Action không tạo ra một RDD mới từ một RDD hiện có. Thay vào đó, chúng thực hiện một số tính toán trên dữ liệu và trả về kết quả cho chương trình điều khiển.
Có ba loại Action chính trong Spark:
-
Action để xem dữ liệu trong console: Các hàm như
collect(),count(),first(),take(), vàtakeSample()được sử dụng để xem dữ liệu trong console. Hàmcollect()trả về tất cả các phần tử của RDD dưới dạng một mảng cho chương trình điều khiển (tức là Driver - là bộ điều phối và phân chia tác vụ (task) cho các Executors). Hàmcount()trả về số lượng phần tử trong RDD. Hàmfirst()vàtake()trả về phần tử đầu tiên và một số lượng phần tử đầu tiên của RDD. HàmtakeSample()trả về một mẫu ngẫu nhiên của RDD. -
Action để thu thập dữ liệu vào cấu trúc dữ liệu gốc trong chương trình điều khiển: Các hàm như
reduce(),fold(),aggregate(),sum(),mean(),stdev(), vàvariance()được sử dụng để thu thập dữ liệu vào cấu trúc dữ liệu gốc trong chương trình điều khiển. Hàmreduce()áp dụng một hàm cho tất cả các phần tử của RDD và trả về một giá trị duy nhất. Hàmfold()giống như hàmreduce(), nhưng nó bắt đầu với một giá trị khởi tạo. Hàmaggregate()cũng giống như hàmreduce(), nhưng nó có thể trả về một kết quả có kiểu dữ liệu khác với kiểu dữ liệu của phần tử trong RDD. -
Action để ghi vào nguồn dữ liệu đầu ra: Các hàm như
saveAsTextFile(),saveAsSequenceFile(),saveAsObjectFile(), vàsaveAsHadoopDataset()được sử dụng để ghi RDD vào nguồn dữ liệu đầu ra. HàmsaveAsTextFile()ghi RDD vào một tệp văn bản. HàmsaveAsSequenceFile()ghi RDD vào một tệp chuỗi. HàmsaveAsObjectFile()ghi RDD vào một tệp đối tượng. HàmsaveAsHadoopDataset()ghi RDD vào một tập dữ liệu Hadoop.
from pyspark import SparkContext
sc = SparkContext("local", "First Spark App")
# Create an RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# Action to view data in console
print(rdd.collect()) # Output: [1, 2, 3, 4, 5]
print(rdd.count()) # Output: 5
print(rdd.first()) # Output: 1
print(rdd.take(3)) # Output: [1, 2, 3]
print(rdd.takeSample(False, 3)) # Output: [2, 1, 3] (random sample)
# Action to collect data into original data structure in driver program
print(rdd.reduce(lambda a, b: a + b)) # Output: 15
print(rdd.fold(0, lambda a, b: a + b)) # Output: 15
print(rdd.aggregate((0, 0),
(lambda acc, value: (acc[0] + value, acc[1] + 1)),
(lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1])))) # Output: (15, 5)
# Action to write to output data source
rdd.saveAsTextFile("output.txt")
Số lượng phân vùng (Number of partition)
Số lượng phân vùng trong PySpark đề cập đến số lượng phân chia logic của dữ liệu. Đây là một khía cạnh cơ bản của tính toán phân tán trong Spark, vì nó xác định cách dữ liệu được chia nhỏ trên cụm. Mỗi phân vùng là một khối dữ liệu riêng biệt có thể được xử lý độc lập trên một nút khác nhau trong cụm. Số lượng phân vùng có thể được chỉ định khi tạo một RDD bằng cách sử dụng hàm parallelize(), hoặc nó có thể được thay đổi sau đó bằng cách sử dụng các hàm repartition() hoặc coalesce(). Số lượng phân vùng tối ưu thường phụ thuộc vào trường hợp sử dụng cụ thể và cấu hình của cụm.
Số lượng phân vùng là một yếu tố quan trọng ảnh hưởng đến hiệu suất của chương trình PySpark của bạn. Có quá ít phân vùng có thể dẫn đến độ parallelism thấp, trong khi có quá nhiều phân vùng có thể dẫn đến overhead lịch trình (schedule).
Chốt lại
Việc hiểu rõ sự khác biệt giữa action và transformation trong Spark là rất quan trọng để viết mã Spark hiệu quả và tối ưu hóa các ứng dụng Spark.
Action trong Spark là các hoạt động trả về một giá trị cho chương trình điều khiển. Khác với transformation, action không tạo ra một RDD mới từ một RDD hiện có. Thay vào đó, chúng thực hiện một số tính toán trên dữ liệu và trả về kết quả cho chương trình điều khiển.
Ngược lại, transformation tạo ra một RDD mới từ một RDD hiện có. Chúng là các hoạt động tạo ra một RDD. Transformation là các hoạt động mà Spark áp dụng lên dữ liệu.
Bằng cách hiểu rõ những khái niệm này, bạn có thể tối ưu hóa các ứng dụng Spark của mình để hoạt động tốt hơn và xử lý dữ liệu một cách hiệu quả hơn. Hãy luôn nhớ rằng, chìa khóa để tối ưu hóa các ứng dụng Spark là giảm thiểu lượng dữ liệu được truyền qua mạng, và để làm được điều này, bạn cần phải hiểu cách hoạt động của action và transformation trong Spark.