- File format là gì?
- Row và Columnar File format
- Avro Row-based format - Đặc trưng và công dụng
- ORC - Optimized Row Columnar format - Đặc trưng và công dụng
- Parquet Columnar File format
Khi làm việc với dữ liệu, đặc biệt là dữ liệu lớn, việc lựa chọn định dạng lưu trữ file đúng từ ban đầu không những giúp ích rất nhiều cho bài toán về tối ưu chi phí lưu trữ, khả năng phân tích sau này cũng như là tiết kiệm chi phí tính toán. Bài viết này sẽ giúp các bạn có góc nhìn về sự khác biệt giữa định dạng file ORC, Parquet và Avro, bao gồm các trường hợp sử dụng tối ưu của chúng, và sâu hơn nữa vào các phương pháp hay nhất cho việc lưu trữ dữ liệu trên Cloud.
File format là gì?
File format là cách dữ liệu được lưu trữ trên đĩa. Các dạng file format như CSV có hay Json, việc lưu trữ và xử lý dữ liệu với những loại dữ liệu lớn lên tới hàng Terabyte sẽ rất là khó khăn và tốn kém chi phí (Json File yêu cầu chi phí tính toán lớn với các dạng dữ liệu lồng - Nested) trong khi đó CSV file không có ràng buộc về mặt schema, việc xử lý các bài toán đến Schema Evolution sẽ rất khó khăn. Đặc điểm chung của Json và CSV là dễ đọc (human readble).
Cùng với lượng dữ liệu được sinh ra ngày càng lớn, việc lựa chọn file format để lưu trữ và xử lý dữ liệu là rất quan trọng liên quan đến bài toán chi phí trong Big data - gồm chi phí tính toán và chi phí lưu trữ. Lựa chọn đúng dạng file lưu trữ cho các bài toán cụ thể có thể giúp các bạn tiết kiếm hàng giờ thời gian, và rất nhiều chi phí, tránh việc phải đập đi xây lại các dự án đã được xây dựng.
Ở bài viết này, mình sẽ giải thích cho các bạn một các đặc trưng cơ bản của ba loại File format thường được sử dụng trong tính toán và lưu trữ với dữ liệu lớn. Đi qua các bài toán và các usecase của từng loại file format và một số lợi ích của nó. Không có loại file format nào là tốt nhất, việc của các bạn là lựa chọn dạng file format lưu trữ phù hợp nhất cho bài toán của các bạn.
Row và Columnar File format
Row-based file format
Row-based file format là một cách tổ chức dữ liệu trong đó mỗi hàng (row) chứa một bản ghi của dữ liệu. Trong một file format dựa trên hàng, dữ liệu được lưu trữ theo từng hàng một cách tuần tự. Điều này có nghĩa là tất cả dữ liệu liên quan đến một bản ghi cụ thể được lưu trữ cùng nhau, hàng này tiếp theo hàng khác. Điều này giúp tối ưu hóa việc đọc và ghi dữ liệu theo từng bản ghi, làm cho nó phù hợp với các ứng dụng yêu cầu xử lý dữ liệu theo từng bản ghi một cách nhanh chóng.
Một số đặc điểm của row-based file format bao gồm:
- Phù hợp với các hệ thống cần truy cập và xử lý dữ liệu theo từng bản ghi.
- Dễ dàng thêm hoặc cập nhật dữ liệu vì mỗi bản ghi được lưu trữ độc lập.
- Hiệu suất đọc và ghi cao khi làm việc với dữ liệu theo từng bản ghi.
- Tuy nhiên, khi cần truy cập đến một số cột cụ thể từ nhiều bản ghi, hiệu suất có thể không được tối ưu so với columnar file format.
Một ưu điểm khác của Avro file format là nó hỗ trợ schema evolution, điều này giúp cho việc thêm hoặc cập nhật dữ liệu trở nên dễ dàng hơn. Ví dụ về row-based file format bao gồm CSV, JSON, và Avro.
Columnar file format
Columnar file format là một cách tổ chức dữ liệu trong đó dữ liệu được lưu trữ và quản lý theo cột thay vì theo hàng. Điều này có nghĩa là tất cả dữ liệu của một cột được lưu trữ cùng nhau, giúp tối ưu hóa việc truy vấn và xử lý dữ liệu trên các cột đó. Điều này làm cho columnar file format trở nên lý tưởng cho các hệ thống phân tích dữ liệu lớn, nơi mà việc truy vấn và xử lý dữ liệu thường xuyên xảy ra trên một số cột nhất định chứ không phải trên toàn bộ bản ghi (chúng ta chỉ lựa chọn 1 số lượng cột cố định chứ không phải là load toàn bộ bảng lên.)
Một số đặc điểm của columnar file format bao gồm:
- Hiệu suất cao trong việc truy vấn dữ liệu: Do dữ liệu được tổ chức theo cột, việc truy vấn và xử lý dữ liệu trên các cột cụ thể trở nên nhanh chóng và hiệu quả.
- Nén dữ liệu hiệu quả: Dữ liệu cùng loại được lưu trữ cạnh nhau giúp việc nén dữ liệu trở nên hiệu quả hơn, giảm chi phí lưu trữ. (đặc biệt dữ liệu trên từng cột nhiều khả năng là giống nhau)
Ứng dụng: Parquet file lý tưởng cho các bài toán lưu trữ (data được nén), các bài toán yêu cầu tính toán theo cột (aggregate như sum hay count,…). Parquet file hiện tại được hỗ trợ hầu hết trên các ngôn ngữ lập trình, hay là các Compute engine như Spark, Flink hay Trino,…
Avro Row-based format - Đặc trưng và công dụng
Avro là một dạng file format dựa trên hàng (row-based), được phát triển bởi Apache Foundation. Nó được thiết kế để hỗ trợ việc lưu trữ và truyền tải dữ liệu một cách hiệu quả trong môi trường phân tán. Avro sử dụng JSON để định nghĩa schema, giúp việc truyền tải dữ liệu giữa các hệ thống khác nhau trở nên dễ dàng hơn.
Đặc trưng của Avro
- Schema Evolution: Avro hỗ trợ schema evolution, cho phép schema được thay đổi theo thời gian mà không làm ảnh hưởng đến dữ liệu đã được lưu trữ. Điều này giúp việc quản lý dữ liệu trở nên linh hoạt hơn.
- Serialization và Deserialization hiệu quả: Avro cung cấp cơ chế serialization và deserialization nhanh chóng và hiệu quả, giúp giảm dung lượng lưu trữ và tăng tốc độ truyền tải dữ liệu. Mình từng làm việc với file Avro khi đọc data từ Kafka - và ghi data xuống Kafka, các file khi đọc và viết bằng Kafka sẽ kèm theo Schema nên các bài toán xử lý tới Schema evolution sẽ khá dễ dàng, đồng thời Avro file được lưu dưới dạng Binary, giúp cho việc lưu trữ tốn ít chi phí hơn.
- Tích hợp tốt với các công nghệ Big Data: Avro được tích hợp sẵn trong nhiều công nghệ Big Data như Apache Hadoop, Apache Spark, và Apache Kafka, giúp việc xử lý dữ liệu lớn trở nên thuận tiện hơn.
- Hỗ trợ nhiều ngôn ngữ lập trình: Avro có thư viện hỗ trợ cho nhiều ngôn ngữ lập trình phổ biến như Java, Python, C#, và Ruby, giúp việc phát triển ứng dụng trở nên dễ dàng.
Công dụng của Avro
- Lưu trữ dữ liệu: Avro là lựa chọn phù hợp cho việc lưu trữ dữ liệu lớn với yêu cầu về hiệu suất cao và dung lượng lưu trữ thấp.
- Truyền tải dữ liệu: Avro được sử dụng rộng rãi trong việc truyền tải dữ liệu giữa các hệ thống và ứng dụng, nhất là trong các hệ thống phân tán.
- Xử lý dữ liệu trong Big Data: Với khả năng tích hợp cao và hỗ trợ schema evolution, Avro là lựa chọn tốt cho việc xử lý và phân tích dữ liệu lớn trong các dự án Big Data.
Avro cung cấp một giải pháp hiệu quả cho việc lưu trữ và xử lý dữ liệu trong môi trường Big Data, giúp giảm chi phí và tăng hiệu suất xử lý dữ liệu.
Tuy nhiên, không phải lúc nào việc lựa chọn file format cũng dễ dàng. Có một số hạn chế và thách thức mà các bạn cũng cần phải xem xét khi quyết định sử dụng file format nào. Dưới đây là một số hạn chế cụ thể:
-
Tính tương thích (compatibility): Không phải tất cả các công cụ và hệ thống đều hỗ trợ mọi loại file format. Ví dụ, một số hệ thống có thể không hỗ trợ đọc hoặc viết dữ liệu dưới dạng Avro một cách hiệu quả. Vấn đề này các bạn cần phải xem xét ngôn ngũ hay engine đang sử dụng có hỗ trợ Avro hiệu quả không.
-
Độ phức tạp: Một số file format, đặc biệt là những định dạng tối ưu cho việc nén và truy vấn dữ liệu như Parquet, có thể yêu cầu một độ phức tạp cao hơn trong việc xử lý và quản lý.
-
Yêu cầu về hiệu suất: Mặc dù columnar file formats như Parquet có thể cung cấp hiệu suất truy vấn dữ liệu cao, nhưng chúng có thể không phù hợp cho các ứng dụng yêu cầu hiệu suất ghi dữ liệu cao.
-
Quản lý Schema: Các file format hỗ trợ schema evolution như Avro đòi hỏi việc quản lý schema một cách cẩn thận, đặc biệt khi schema thay đổi theo thời gian.
Bằng cách hiểu rõ các hạn chế và thách thức này, các kỹ sư dữ liệu có thể đưa ra quyết định thông minh hơn về việc lựa chọn file format phù hợp cho nhu cầu cụ thể của dự án của họ.
Ứng dụng: các dạng file Avro format thông thường được sử dụng khi xử lý dữ liệu dạng record như trên Kafka (bằng cách enforce schema và binary encoding), phục vụ cho các tác vụ ghi nhiều (write heavy) và đọc ít (read light).
ORC - Optimized Row Columnar format - Đặc trưng và công dụng
ORC (Optimized Row Columnar) format là một định dạng file được tối ưu hóa cho việc lưu trữ dữ liệu dạng hàng và cột, phát triển bởi Apache Hive. Định dạng này được thiết kế để cung cấp một hiệu suất cao trong việc truy vấn và xử lý dữ liệu lớn với một số tác vụ(operation) như aggregate hay group by, đồng thời giảm dung lượng lưu trữ thông qua nén dữ liệu hiệu quả.
ORC được Apache Hive (query engine) tối ưu cho việc lưu trữ và query (vectorize row-based) nên thông thường sẽ được sử dụng với các hệ thống của Hive. Trong khi một số query engine khác như Spark và FLink lại tập trung tối ưu dạng vectorized theo dạng Columnar format như Parquet. Khi sử dụng ORC cần phải lưu ý điểm này.
Đây là hình minh hoạ (Medium source) khi lưu trữ data dưới dạng ORC
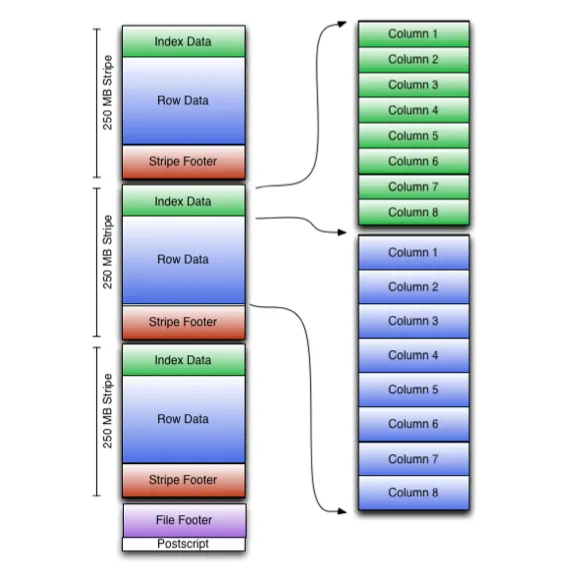
Đặc trưng của ORC
- Hiệu suất truy vấn cao: ORC sử dụng cấu trúc dữ liệu cột (columnar) để tối ưu hóa việc truy vấn, giúp tăng tốc độ truy vấn dữ liệu.
- Nén dữ liệu hiệu quả: Dữ liệu được nén một cách hiệu quả, giảm dung lượng lưu trữ cần thiết và tăng tốc độ truyền tải dữ liệu.
- Hỗ trợ cho việc xử lý dữ liệu phức tạp: ORC hỗ trợ các cấu trúc dữ liệu phức tạp như mảng, cấu trúc (struct), và bản đồ (map), giúp việc xử lý dữ liệu trở nên linh hoạt hơn.
- Tích hợp với các công nghệ Big Data: ORC được tích hợp sẵn trong các công nghệ Big Data như Apache Hive và Apache Spark, giúp việc xử lý và phân tích dữ liệu lớn trở nên thuận tiện hơn.
- Hỗ trợ ACID transactions: ORC hỗ trợ các giao dịch ACID, giúp quản lý dữ liệu trong các môi trường đa người dùng một cách hiệu quả.
Công dụng của ORC
- Lưu trữ dữ liệu lớn: Với khả năng nén dữ liệu và hiệu suất truy vấn cao, ORC là lựa chọn lý tưởng cho việc lưu trữ dữ liệu lớn.
- Phân tích dữ liệu: ORC được thiết kế để tối ưu hóa việc truy vấn dữ liệu, làm cho nó trở thành lựa chọn tốt cho các ứng dụng phân tích dữ liệu.
- Hệ thống Big Data: Với tính tương thích cao và hỗ trợ cho việc xử lý dữ liệu phức tạp, ORC phù hợp với các hệ thống Big Data, cung cấp một giải pháp hiệu quả cho việc lưu trữ và xử lý dữ liệu.
ORC cung cấp một giải pháp lưu trữ dữ liệu hiệu quả và linh hoạt, giúp giảm chi phí lưu trữ và tăng hiệu suất xử lý dữ liệu trong các ứng dụng Big Data.
Parquet Columnar File format
Parquet là một định dạng file columnar được sử dụng trong Hadoop ecosystem, phát triển bởi Apache Software Foundation. Định dạng này được thiết kế để tối ưu hóa việc lưu trữ và truy vấn dữ liệu lớn, đặc biệt là dữ liệu dạng cột. Parquet hỗ trợ nén dữ liệu và encoding hiệu quả, giúp giảm dung lượng lưu trữ và tăng tốc độ truy vấn dữ liệu.
Ví dụ về phép tính toán trên cột với Parquet: Giả sử bạn muốn tính tổng của một cột giá trị trong một bảng dữ liệu lớn. Với Parquet, bạn chỉ cần truy cập cột đó và thực hiện phép tính, mà không cần phải tải toàn bộ bảng dữ liệu vào bộ nhớ so với khi sử dụng lưu trữ hạng hàng. Điều này giúp tăng tốc độ xử lý và giảm dung lượng RAM cần thiết.
Một trong những đặc trưng nổi bật của Parquet là khả năng lưu trữ dữ liệu theo cột thay vì theo hàng. Điều này giúp tối ưu hóa việc truy vấn dữ liệu khi chỉ cần một số cột nhất định từ bảng dữ liệu, giảm thiểu việc đọc dữ liệu không cần thiết từ ổ cứng. Ngoài ra, Parquet hỗ trợ các cấu trúc dữ liệu phức tạp như nested objects và arrays, cung cấp khả năng lưu trữ dữ liệu linh hoạt và hiệu quả.
Lợi ích của việc sử dụng Parquet không chỉ dừng lại ở việc giảm dung lượng lưu trữ và tăng tốc độ truy vấn. Parquet còn giúp tăng hiệu suất xử lý dữ liệu trong các hệ thống phân tích dữ liệu lớn như Apache Hadoop và Apache Spark. Việc sử dụng Parquet giúp giảm thời gian xử lý dữ liệu, từ đó tăng hiệu quả của các quy trình phân tích dữ liệu.
Các usecase phổ biến của Parquet bao gồm lưu trữ dữ liệu lớn trong các hệ thống Hadoop và Spark, xử lý và phân tích dữ liệu lớn, và làm dữ liệu nguồn cho các công cụ truy vấn dữ liệu như Apache Drill và Apache Impala. Parquet cũng được sử dụng rộng rãi trong các hệ thống data warehouse và data lake, nơi mà hiệu suất truy vấn và khả năng lưu trữ dữ liệu hiệu quả là yếu tố quan trọng.
Tóm lại, Parquet là một lựa chọn tối ưu cho việc lưu trữ và xử lý dữ liệu lớn trong các hệ thống Big Data, nhờ vào khả năng lưu trữ dữ liệu theo cột, hỗ trợ nén và encoding dữ liệu hiệu quả, và tối ưu hóa hiệu suất truy vấn.