Trong phần này, chúng ta sẽ đi qua quá trình setup môi trường và thực hiện một số thao tác cơ bản với Kafka bằng cách sử dụng Docker và Docker compose - phần setup khá đơn giản chỉ cần các bạn cài đặt Docker Desktop. Để bắt đầu, bạn cần cài đặt Kafka và Zookeeper trên máy của mình. Kafka sử dụng Zookeeper để quản lý và điều phối cluster, vì vậy việc cài đặt Zookeeper là bắt buộc.
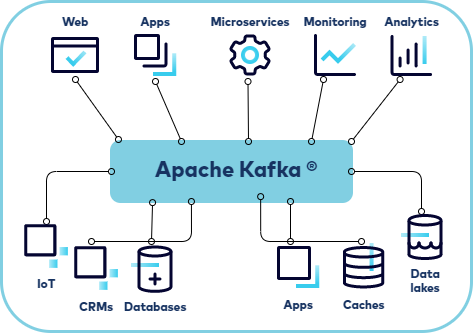
Kafka từ cơ bản tới nâng cao - Setup môi trường và thao tác cơ bản
Cài đặt và cấu hình Kafka - sử dụng Docker
Để thiết lập môi trường Kafka sử dụng Docker, bạn cần thực hiện các bước sau:
-
Đầu tiên, bạn cần có Docker và Docker Compose được cài đặt trên máy của mình. Bạn có thể tải về và cài đặt từ trang chính thức của Docker.
-
Tiếp theo, clone repository chứa mã nguồn cấu hình Docker Compose cho Kafka, Zookeeper và Spark. Sử dụng lệnh sau để clone repository từ GitHub:
git clone https://github.com/akatekhanh/geeksdata.git
# Run docker compose to start Kafka container and Pyspark Notebook container
# -d means detach: run container in silence
docker compose up -d
Các bạn có thể mở file docker để tìm hiểu các Service bên trong đó:
version: '3.1'
services:
spark:
build: .
volumes:
- .:/home/jovyan/work
ports:
- "8888:8888"
kafka:
image: wurstmeister/kafka
ports:
- "9092:9092"
- "9094:9094"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_LISTENERS: INTERNAL://0.0.0.0:9092,OUTSIDE://0.0.0.0:9094
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka:9092,OUTSIDE://localhost:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
volumes:
- /var/run/docker.sock:/var/run/docker.sock
depends_on:
- zookeeper
kafka-ui:
image: provectuslabs/kafka-ui
ports:
- "8080:8080"
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092
DYNAMIC_CONFIG_ENABLED: 'true'
depends_on:
- kafka
zookeeper:
image: confluentinc/cp-zookeeper:latest
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
File docker compose bao gồm các dịch vụ sau:
-
Spark: Dịch vụ này xây dựng một container từ Dockerfile trong thư mục hiện tại. Nó chia sẻ thư mục hiện tại của máy host với thư mục
/home/jovyan/worktrong container và mở cổng8888để truy cập Jupyter Notebook. -
Kafka: Sử dụng image
wurstmeister/kafkavà cấu hình các biến môi trường nhưKAFKA_BROKER_IDvàKAFKA_ZOOKEEPER_CONNECTđể kết nối với Zookeeper. Cổng9092được mở cho Kafka và cấu hình listeners để cho phép kết nối từ bên trong và bên ngoài container. -
Kafka-UI: Dịch vụ này sử dụng image
provectuslabs/kafka-uiđể cung cấp một giao diện người dùng qua web cho việc quản lý và giám sát Kafka cluster. Nó kết nối với Kafka thông qua cổng9092và mở cổng8080để truy cập từ trình duyệt. -
Zookeeper: Sử dụng image
confluentinc/cp-zookeepervà cấu hình các biến môi trường nhưZOOKEEPER_CLIENT_PORTvàZOOKEEPER_TICK_TIME. Cổng2181được mở cho Zookeeper để kết nối với Kafka.
Cấu hình này giúp thiết lập một môi trường đơn giản để bắt đầu làm việc với Kafka, bao gồm việc produce và consume message, quản lý topic, và giám sát cluster thông qua Kafka UI. Đồng thời, việc tích hợp Spark giúp các bạn có thể kết nối tới Kafka và sủ dụng ngôn ngữ Python.
Các bạn có thể kiếm tra các service đang được chạy trên Docker và xem Kafka UI để có thể trực quan hoá Kafka message của mình.
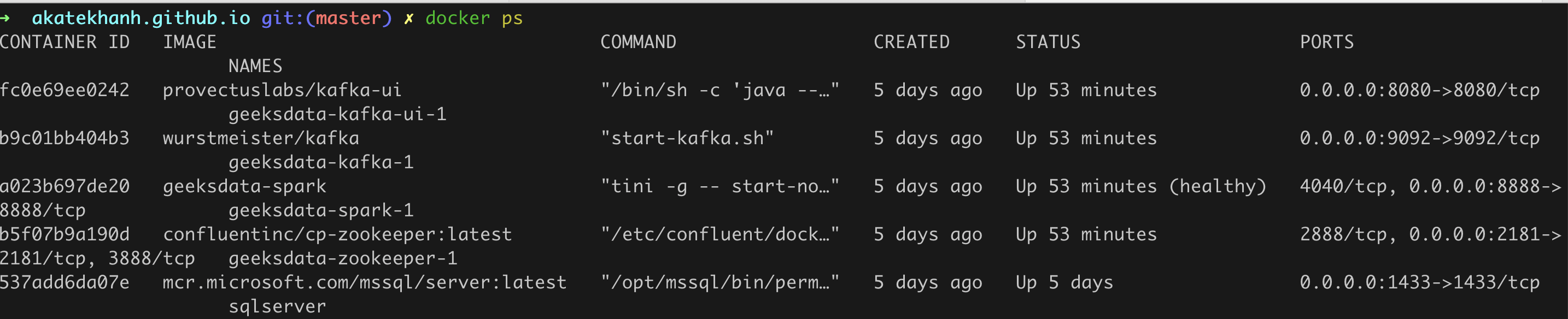
Truy cập vào localhost:8080 để xem Kafka UI
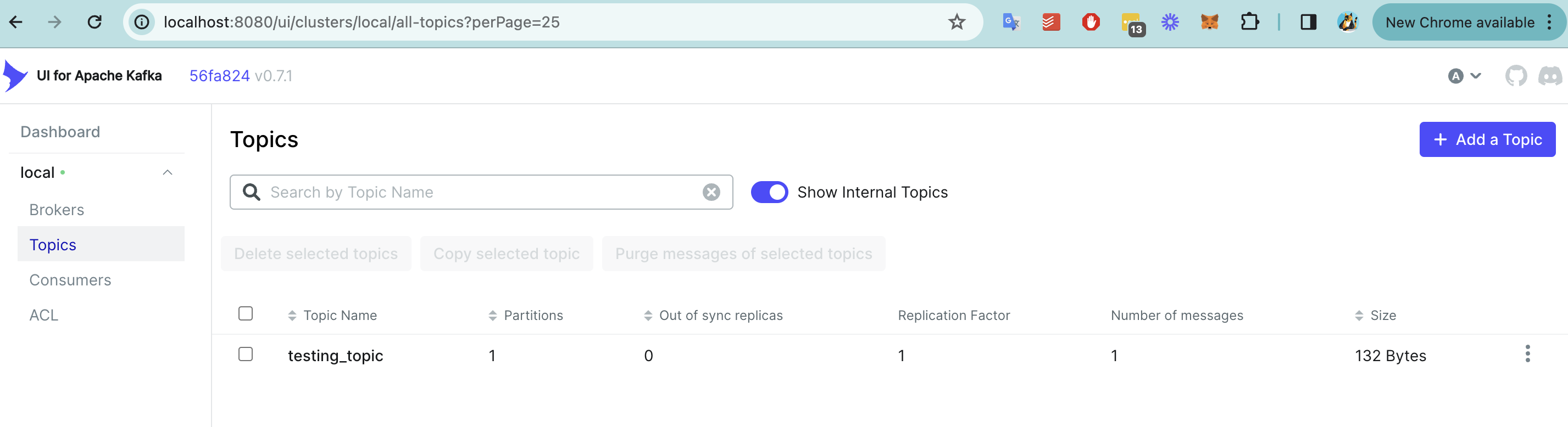
2. Thao tác cơ bản với Kafka
Tạo và produce một vài message vào Kafka
from kafka import KafkaProducer
import json
# Initialize Kafka producer
producer = KafkaProducer(bootstrap_servers=['localhost:9094'],
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
# Message to be sent
message = {"data": "Sample message to Kafka topic"}
# Topic to send the message
topic_name = 'sample_topic'
# Send message to Kafka
producer.send(topic_name, value=message)
# Ensure all messages are sent
producer.flush()
print("Message sent to Kafka topic successfully.")
Trong đoạn code trên, chúng ta đang thực hiện việc gửi một message đến Kafka sử dụng KafkaProducer từ thư viện kafka-python. Dưới đây là giải thích chi tiết từng bước:
-
Import thư viện: Đầu tiên, chúng ta import
KafkaProducertừ thư việnkafkavà thư việnjsonđể làm việc với dữ liệu dạng JSON. - Khởi tạo Kafka Producer:
bootstrap_servers=['localhost:9094']: Định nghĩa server của Kafka mà producer sẽ kết nối đến. Trong trường hợp này, Kafka đang chạy trên localhost với port9094.value_serializer=lambda v: json.dumps(v).encode('utf-8'): Định nghĩa cách thức serialize dữ liệu trước khi gửi đến Kafka. Ở đây, chúng ta chuyển dữ liệu từ dạng dictionary sang dạng JSON string và encode nó sang utf-8.
-
Tạo message: Tạo một dictionary
messagevới key là"data"và value là một string"Sample message to Kafka topic". -
Định nghĩa topic: Tên của topic mà chúng ta muốn gửi message đến là
sample_topic. - Gửi message đến Kafka:
- Sử dụng phương thức
sendcủa producer để gửi message đến topic đã định. Phương thức này nhận vào tên topic và giá trị của message. producer.flush(): Đảm bảo rằng tất cả các messages đều được gửi đi trước khi tiếp tục thực hiện các lệnh tiếp theo. Điều này hữu ích trong trường hợp có nhiều messages cần được gửi và bạn muốn đảm bảo rằng tất cả đều đã được xử lý.
- Sử dụng phương thức
- Thông báo: In ra thông báo
"Message sent to Kafka topic successfully."sau khi message đã được gửi thành công.
Các bạn có thể tìm tải đoạn code trên ở Link github của mình.
Truy cập vào localhost:8080 để kiểm tra xem message đã được gửi đến Kafka hay chưa.
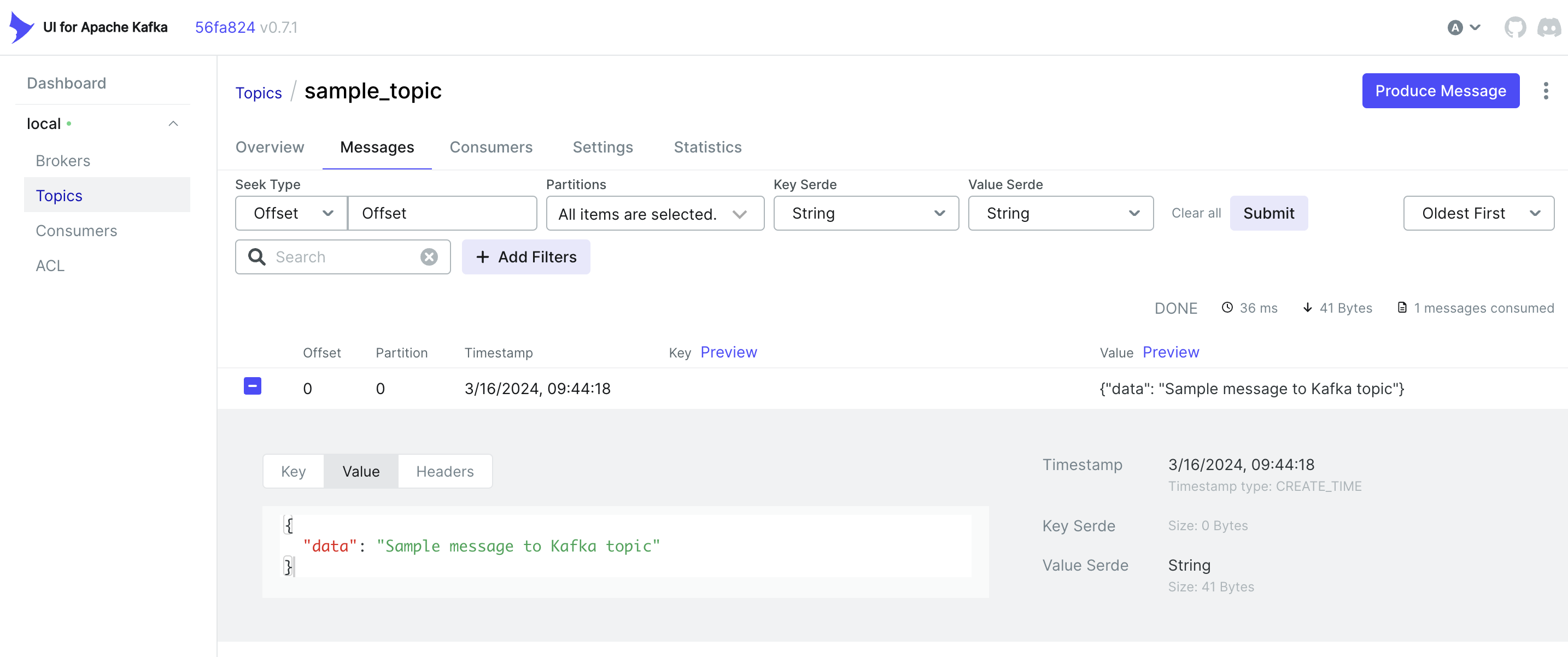
Consume message từ Kafka
from kafka import KafkaConsumer
# Initialize Kafka consumer
consumer = KafkaConsumer('sample_topic',
bootstrap_servers=['localhost:9094'],
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='my-group',
value_deserializer=lambda x: json.loads(x.decode('utf-8')))
print("Starting the consumer")
# Consume messages
for message in consumer:
print(f"Received message: {message.value}")
Trong đoạn code này, chúng ta đang thực hiện việc tiêu thụ (consume) các message từ Kafka sử dụng KafkaConsumer từ thư viện kafka-python. Dưới đây là giải thích chi tiết từng bước:
- Khởi tạo Kafka Consumer:
bootstrap_servers=['localhost:9094']: Định nghĩa server của Kafka mà consumer sẽ kết nối đến. Trong trường hợp này, Kafka đang chạy trên localhost với port9094.auto_offset_reset='earliest': Định nghĩa việc bắt đầu consume message từ đầu của log.enable_auto_commit=True: Tự động commit offset của message cuối cùng mà KafkaConsumer đã xử lý.group_id='my-group': Định nghĩa ID của consumer group.value_deserializer=lambda x: json.loads(x.decode('utf-8')): Định nghĩa cách thức deserialize dữ liệu khi nhận từ Kafka. Ở đây, chúng ta chuyển dữ liệu từ dạng JSON string sang dictionary.
- Bắt đầu consumer:
- In ra thông báo
"Starting the consumer"để biết là consumer đã bắt đầu hoạt động.
- In ra thông báo
- Consume message:
- Sử dụng vòng lặp
forđể liên tục nhận và xử lý message từ Kafka. Mỗi message nhận được sẽ được in ra màn hình với nội dung là giá trị của message.
- Sử dụng vòng lặp
Đây là kết quả:
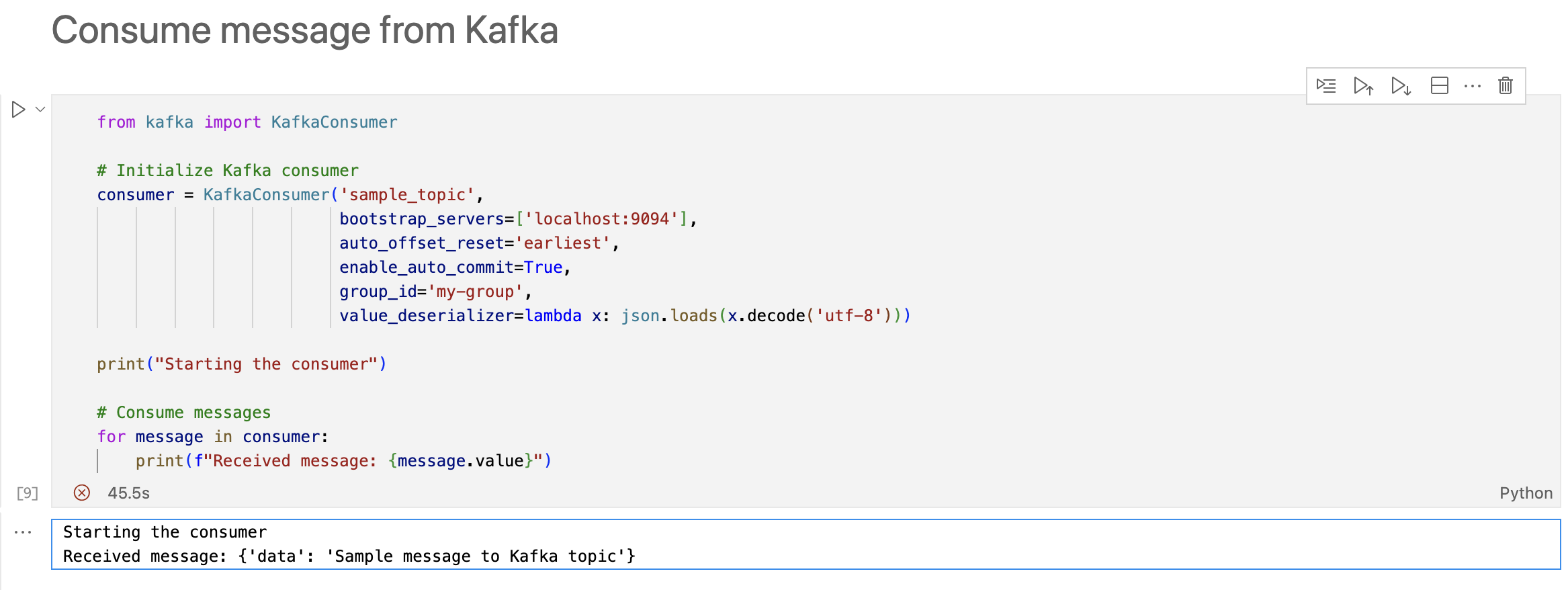
Các bạn có thể tìm tải đoạn code trên ở Link github của mình.
3. Consumer groups
Consumer groups trong Kafka là một khái niệm quan trọng giúp quản lý việc tiêu thụ (consume) dữ liệu từ các topic một cách hiệu quả. Một consumer group bao gồm một hoặc nhiều consumer làm việc cùng nhau để xử lý dữ liệu từ một hoặc nhiều topic. Mỗi consumer trong group sẽ đọc dữ liệu từ một hoặc nhiều partition của topic, giúp tăng tốc độ xử lý dữ liệu và khả năng mở rộng của hệ thống.
Lợi ích của Consumer Groups
- Phân chia công việc: Consumer groups cho phép phân chia dữ liệu của một topic ra nhiều consumer để xử lý song song, giúp tăng hiệu suất xử lý.
- Tăng độ tin cậy: Khi một consumer gặp sự cố, các consumer khác trong group có thể tiếp tục xử lý dữ liệu, giảm thiểu rủi ro mất mát dữ liệu.
- Tự động cân bằng: Kafka tự động cân bằng partition giữa các consumer trong cùng một group, đảm bảo công bằng và hiệu quả trong việc xử lý dữ liệu.
Cách hoạt động
Khi một consumer mới tham gia vào group, Kafka sẽ tự động cân bằng lại các partition giữa các consumer trong group đó. Nếu một consumer rời khỏi group, Kafka cũng sẽ tự động phân phối lại các partition mà consumer đó đang xử lý cho các consumer khác trong group. Điều này giúp đảm bảo rằng dữ liệu luôn được xử lý một cách hiệu quả và không bị gián đoạn.
Ví dụ
Giả sử có một topic với 4 partition và một consumer group với 2 consumer. Kafka có thể phân chia 2 partition cho mỗi consumer để xử lý. Nếu một consumer mới tham gia vào group, Kafka có thể quyết định phân chia lại partition, ví dụ 1 partition cho mỗi consumer, để tối ưu hóa việc xử lý dữ liệu.
Consumer groups là một công cụ mạnh mẽ trong Kafka, giúp tối ưu hóa việc xử lý và tiêu thụ dữ liệu trong các hệ thống phân tán lớn.
Đây là giao diện của consumer group trên Kafka UI
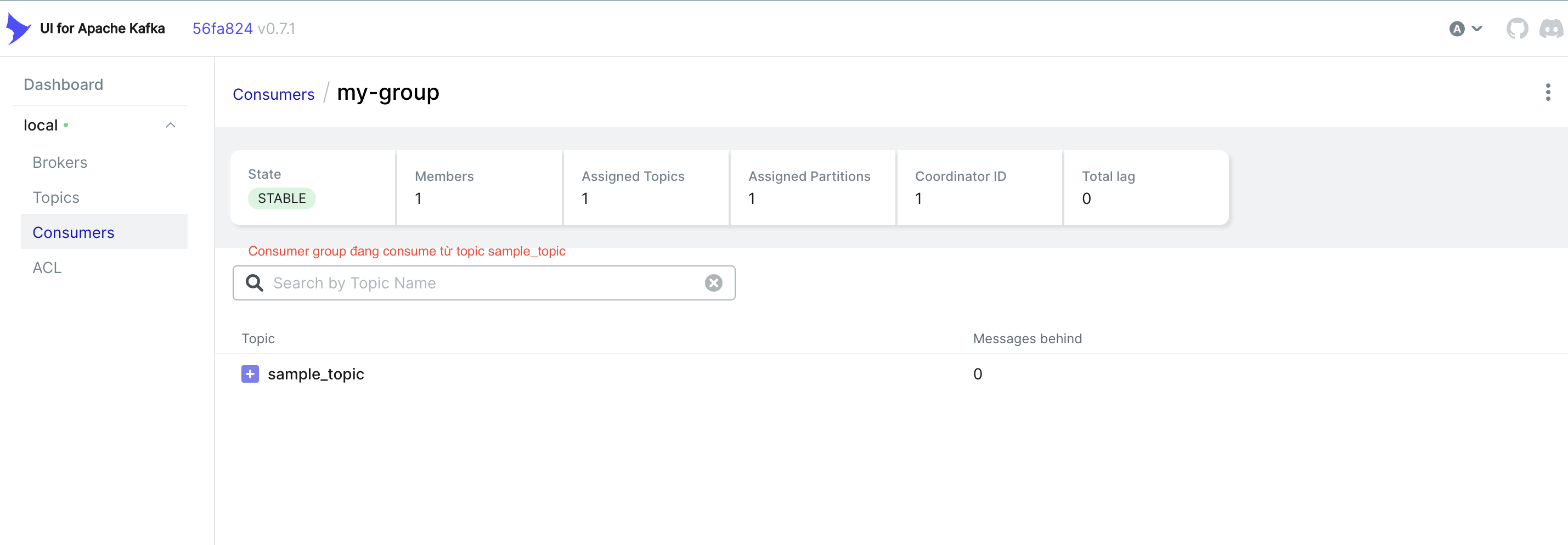
Kết luận
Trong bài viết này, chúng ta đã đi qua một số khái niệm cơ bản và cách thức hoạt động của Kafka trong thực tế. Từ việc khởi tạo Kafka Consumer, bắt đầu consumer và tiêu thụ message, chúng ta có thể thấy Kafka là một công cụ mạnh mẽ và linh hoạt, phù hợp với nhiều nhu cầu khác nhau trong việc xử lý và phân phối dữ liệu.
Consumer groups là một tính năng quan trọng giúp tối ưu hóa việc xử lý dữ liệu từ các topic, bằng cách phân chia công việc giữa các consumer, tăng độ tin cậy và khả năng mở rộng của hệ thống.
Kafka, với kiến trúc mạnh mẽ và khả năng tích hợp cao, đã trở thành một phần không thể thiếu trong hệ sinh thái dữ liệu của nhiều tổ chức và doanh nghiệp. Việc hiểu rõ về cách thức hoạt động và khai thác hiệu quả các tính năng của Kafka sẽ giúp chúng ta xây dựng được những hệ thống xử lý dữ liệu realtime hiệu quả và ổn định.
Hy vọng rằng qua bài viết này, bạn đã có thêm những kiến thức bổ ích về Kafka và có thể áp dụng vào các dự án của mình. Hãy tiếp tục theo dõi và khám phá thêm nhiều kiến thức về Kafka và các công nghệ dữ liệu khác trong các bài viết tiếp theo!