Khi làm việc tron lĩnh vực phần mềm, khá nhiều bạn đã từng nghe tới các khái niệm về hàng đợi Queue, hay message broker chẳng hạn như RabitMQ, ActiveMQ hay Redis(có thể xài Redis làm Cache layer). Còn nếu khi làm việc với data thì mình tin rằng ai cũng từng nghe tới Kafka. Vậy Kafka là gì? Tại sao hầu hết ai làm Data cũng sử dụng nó? Kiến trúc như thế nào và làm sao để sử dụng? Hãy tìm hiểu trong bài viết hôm nay.
- Apache Kafka tổng quan
- Kiến trúc của Kafka - Fundamental Concepts
- Kết thúc phần 1 về khái niệm cơ bản
Apache Kafka tổng quan
Kafka (Apache Kafka) là gì?
Kafka là một hệ thống message broker mã nguồn mở được phát triển bởi Apache Software Foundation. Nó được thiết kế để xử lý dữ liệu dòng lớn (data stream) và phân tán qua nhiều máy chủ. Một số ứng dụng có thể hay gặp như dùng Kafka để lưu trữ dữ liệu như là 1 vùng đệm, data integrity với các hệ thống (lưu trữ dữ liệu dạng event trong Kafka để các ứng dụng khác Consume),…
Trước khi đi sâu hơn để tìm hiểu kiến trúc của Kafka, chúng ta cần hiểu về event, là khái niệm sẽ đi xuyên suốt trong khi làm việc với Kafka.
Event là gì?
Event trong Kafka là gì?
Event trong Kafka là một bản ghi dữ liệu đại diện cho một sự kiện cụ thể xảy ra tại một thời điểm nhất định. Event có thể là một hành động (action), một sự thay đổi trong database được hệ thống capture lại (như tác vụ Insert, Update, Delete,…), một incident, một cú click chuột trên website, một transaction chuyển tiền,… Tất cả các thứ đó đều là event.
Thông thường 1 event có kích thước khá nhỏ (hiếm khi nào 1 event có kích thước lớn), được biểu diễn ở dưới dạng không có cấu trúc như Json, hoặc ở dạng decoded - Avro (dạng này chứa thông tin về schema) hay là Buffer protocol.
Việc đọc - ghi trên Kafka thông qua Event. Mỗi event bao gồm:
- Key (khoá): để xác định phân vùng (partition) mà message thuộc về. Cái này sẽ nói rõ hơn ở phần kiến trúc
- Value(giá trị của message): là thông tin mình muốn lưu trự, như Json, encoded message,…
- Metadata: bao gồm Offset, Timestamp,…
Đây là một ví dụ của Kafka message:
{
"name": "John Doe",
"age": 30,
"city": "New York"
}
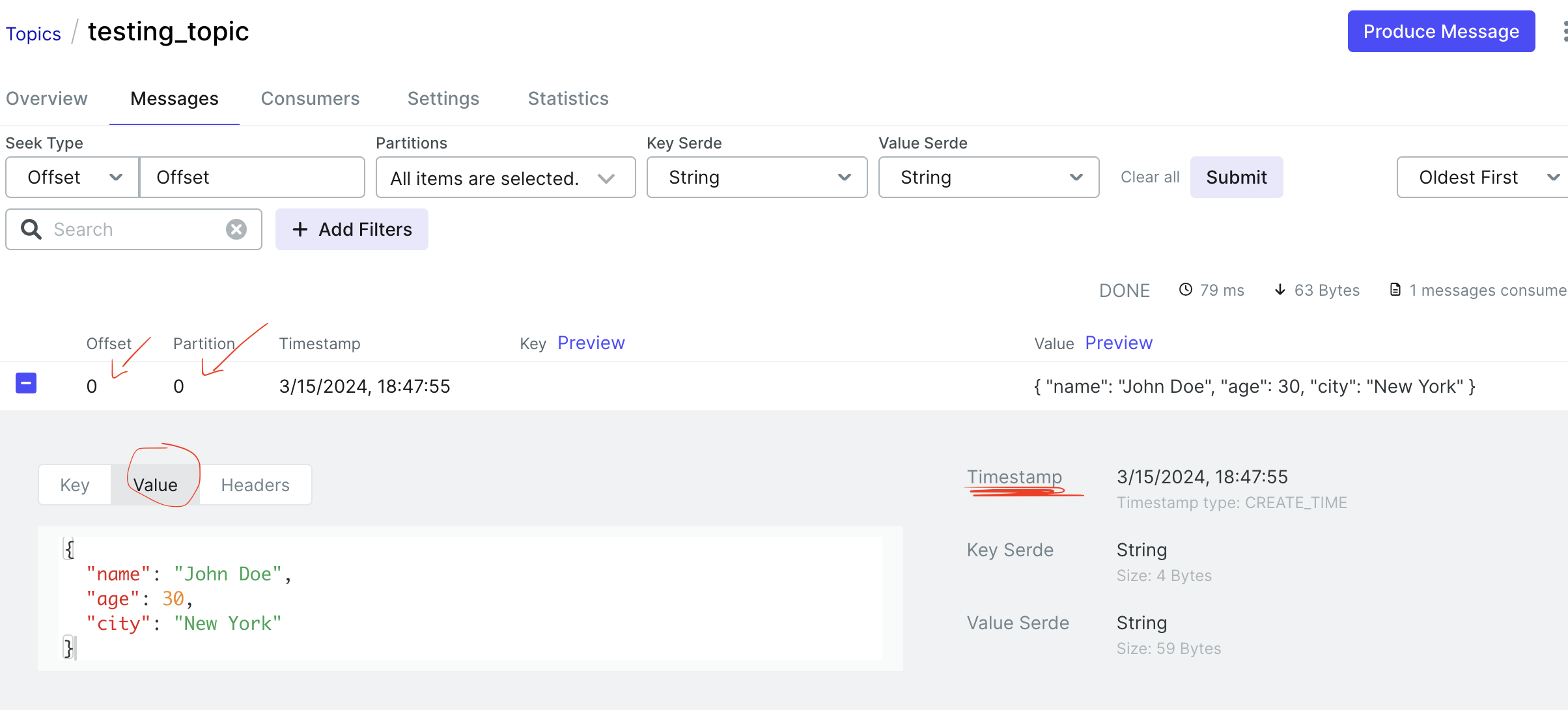 Đây là hình minh hoạ của một message trên Kafka, một message trên Kafka bao gồm Key, Partition, thông tin về message, Timestamp khi Kafka commit message,…
Đây là hình minh hoạ của một message trên Kafka, một message trên Kafka bao gồm Key, Partition, thông tin về message, Timestamp khi Kafka commit message,…
Kiến trúc của Kafka - Fundamental Concepts
Kiến trúc của Kafka dựa trên một số khái niệm cơ bản sau:
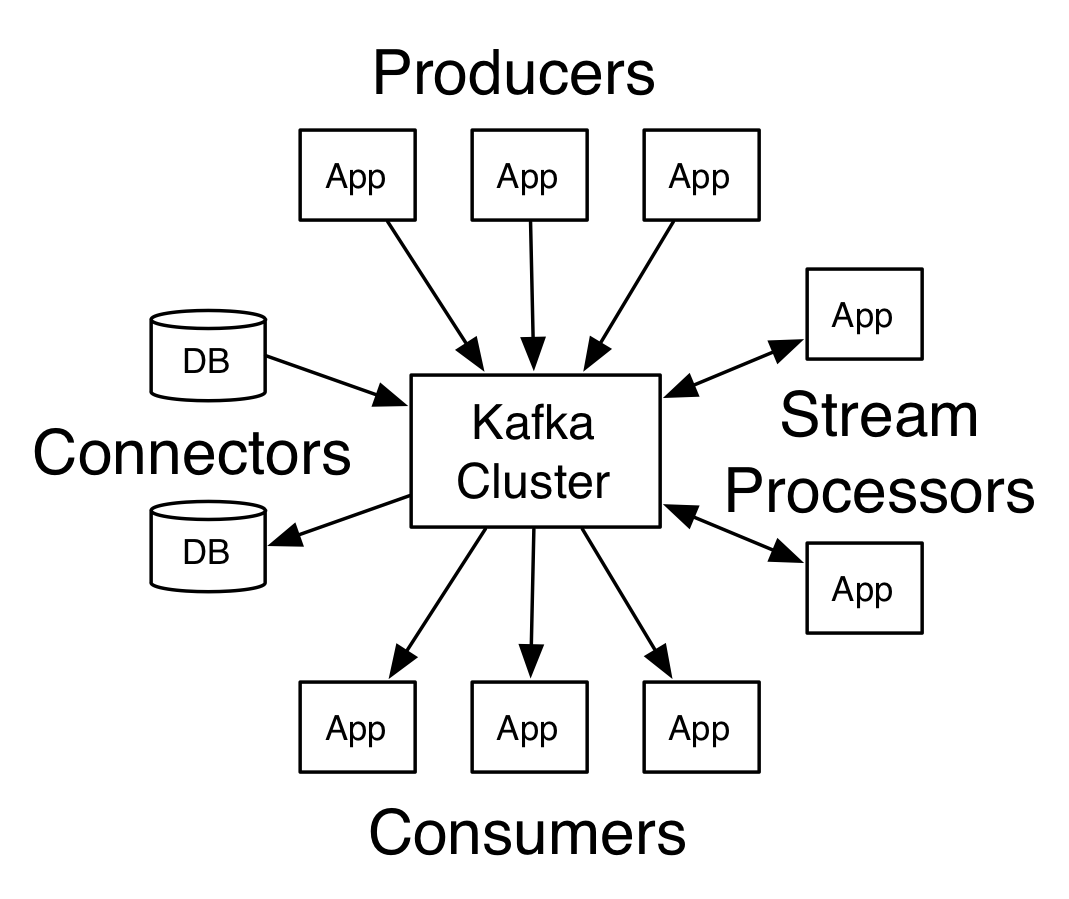
 Để tìm hiểu Kafka, chúng ta cần tìm hiểu về các thành phần kiến trúc trong Kafka và các thành phần tương tác với nó.
Về cơ bản, các thành phần trong Kafka và tương tác với nó sẽ bao gồm:
Để tìm hiểu Kafka, chúng ta cần tìm hiểu về các thành phần kiến trúc trong Kafka và các thành phần tương tác với nó.
Về cơ bản, các thành phần trong Kafka và tương tác với nó sẽ bao gồm:
- Producer: thành phần đẩy message vào Kafka
- Consumer: thành phần kéo message từ Kafka ra và xử lý nó
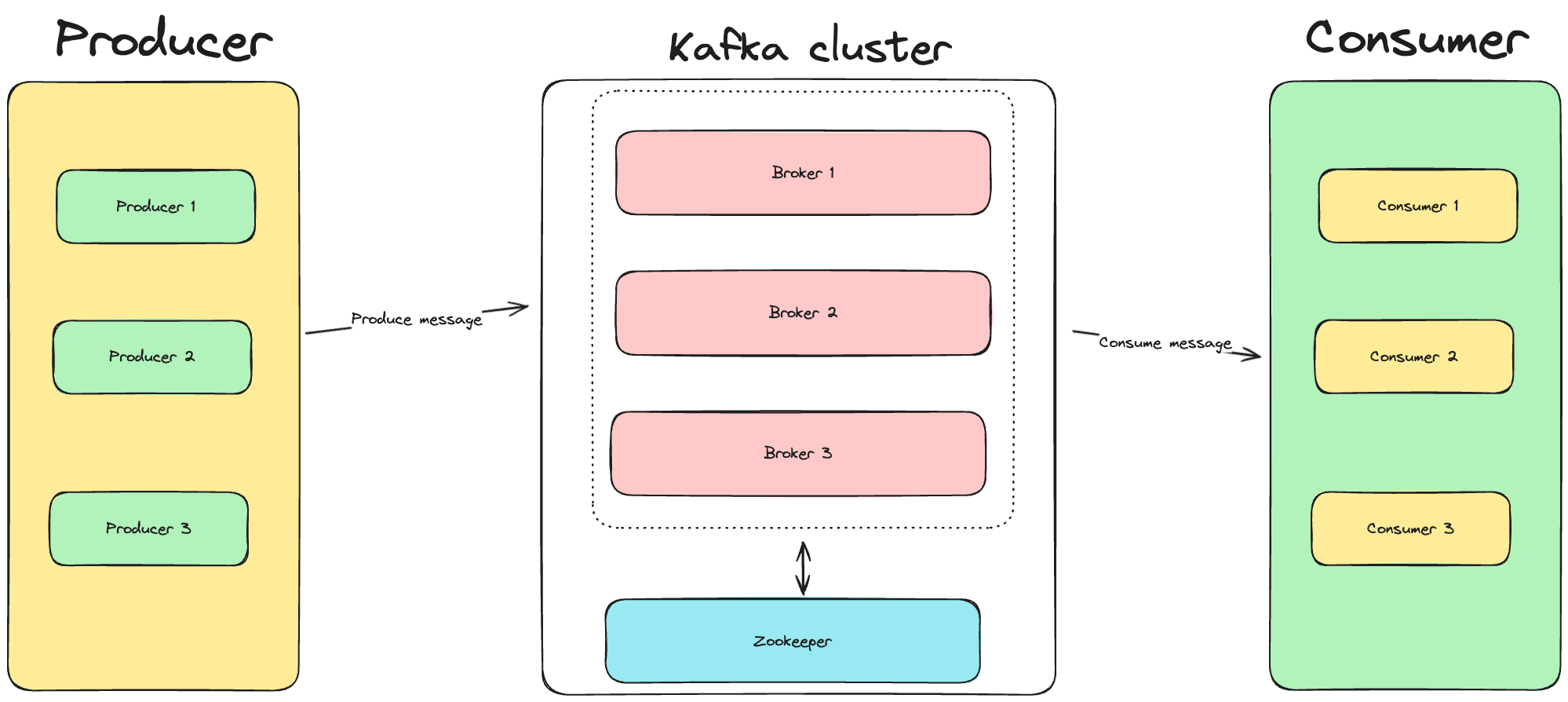
- Kafka cluster: gồm 1 hoặc nhiều broker, mỗi broker có thể gồm 1 hoặc nhiều machine (Kafka là một hệ thống phân tán):
- Mỗi broker có thể chứa 1 hoặc nhiều topic
- Mỗi topic có thể có 1 hoặc nhiều partition -> một broker có thể có nhiều partition
- Thông tin trong Kafka message bao gồm:
- Key: Được sử dụng để xác định partition mà message sẽ được gửi đến.
- Value: Dữ liệu thực tế mà bạn muốn gửi.
- Timestamp: Thời gian mà message được sản xuất.
- Headers: Metadata tùy chọn có thể được thêm vào message.
Producer
Producer là thành phần gửi dữ liệu vào Kafka. Mỗi producer quyết định dữ liệu của mình sẽ được gửi vào partition nào trong một topic cụ thể. Producer có thể chọn partition dựa trên một số chiến lược, như round-robin hoặc sử dụng một key cụ thể để đảm bảo dữ liệu cùng key luôn được gửi vào cùng một partition.
Consumer
Consumer đọc dữ liệu từ Kafka. Một consumer thuộc về một consumer group. Kafka hỗ trợ mô hình consumer group để cho phép một nhóm các consumer cùng đọc dữ liệu từ một topic, với mỗi consumer đọc dữ liệu từ một hoặc nhiều partition. Điều này giúp tăng khả năng mở rộng và độ tin cậy của hệ thống.
Broker
Broker là một server trong Kafka cluster. Một Kafka cluster có thể bao gồm một hoặc nhiều broker. Broker chứa dữ liệu và xử lý các yêu cầu từ producer và consumer. Broker cũng chịu trách nhiệm cho việc sao lưu dữ liệu và cân bằng tải.
Topic
Topic là một danh mục hoặc feed tên mà dữ liệu được lưu trữ. Producer gửi dữ liệu vào các topic và consumer đọc dữ liệu từ các topic này. Mỗi topic có thể được chia thành nhiều partition để tăng khả năng mở rộng.
Partition
Partition là một phần của một topic. Dữ liệu trong một partition được sắp xếp theo thứ tự và không thay đổi - tức là, dữ liệu được ghi vào một partition theo một thứ tự cụ thể và consumer đọc dữ liệu theo thứ tự đó. Partition cũng giúp tăng khả năng mở rộng của Kafka bằng cách phân tán dữ liệu trên nhiều broker.
Offset
Offset là một số đại diện cho vị trí của mỗi bản ghi trong một partition. Mỗi bản ghi trong một partition có một offset duy nhất. Consumer sử dụng offset để theo dõi vị trí của mình trong partition.
Zookeeper
Zookeeper được sử dụng để quản lý và điều phối Kafka cluster. Zookeeper giữ thông tin về các broker, topic, và partition. Nó cũng giúp trong việc điều phối các broker và đảm bảo tính nhất quán trong cluster.
Kiến trúc của Kafka được thiết kế để xử lý dữ liệu streaming một cách hiệu quả, với khả năng mở rộng cao và độ tin cậy. Các khái niệm cơ bản này là nền tảng giúp Kafka trở thành một giải pháp mạnh mẽ cho việc xử lý và lưu trữ dữ liệu streaming.
Kết thúc phần 1 về khái niệm cơ bản
Trong bài viết này, chúng ta đã cùng nhau khám phá kiến trúc cơ bản và các khái niệm quan trọng của Kafka. Từ Producer, Consumer, đến Kafka Cluster và các thành phần khác như Topic, Partition, và Offset, tất cả đều đóng vai trò quan trọng trong việc xây dựng và vận hành một hệ thống Kafka hiệu quả.
Kafka, với khả năng xử lý dữ liệu streaming mạnh mẽ, độ tin cậy cao và khả năng mở rộng linh hoạt, đã trở thành một giải pháp không thể thiếu trong hệ sinh thái dữ liệu hiện đại. Việc hiểu rõ về kiến trúc và cách thức hoạt động của Kafka sẽ giúp chúng ta tận dụng tối đa sức mạnh của nó trong việc xử lý và phân tích dữ liệu real-time.
Hy vọng rằng, qua bài viết này, bạn đã có cái nhìn tổng quan và sâu sắc hơn về Kafka và sẵn sàng áp dụng nó vào các dự án của mình. Hãy tiếp tục theo dõi và khám phá thêm nhiều kiến thức bổ ích về Kafka và các công nghệ dữ liệu khác cùng mình trong các bài viết tiếp theo!
Trong bài viết sau mình và các bạn sẽ cùng đi setup 1 cụm Kakfa cluster trên local và thử thao tác produce và consume message từ nó. Hẹn các bạn ở bài viết sau.