Trong năm qua, dbt đã trở thành một trong những công cụ yêu thích của tôi để biến đổi và phân tích dữ liệu…
- Giới thiệu
dbt- Data build tool và dự án đầu tiên - Tổng quan về Data trong dự án này
- Setup Docker cho Postgres
- Setup DBT profiles và thông tin về Schema, Database và Connection tới Postgres
- Run dbt đầu tiên
- Generate document và xem Lineage trên Web bằng DBT gen docs
- Kết luận
Giới thiệu dbt - Data build tool và dự án đầu tiên
Trong năm qua, dbt đã trở thành một trong những công cụ yêu thích của tôi để biến đổi và phân tích dữ liệu. Nó đã tạo ra sự khác biệt lớn trong cách tôi có thể làm việc một cách hiệu quả và tự tin hơn vào độ chính xác của kết quả của mình. Mình thấy rằng nó rất hữu ích trong việc tối ưu hóa quy trình dữ liệu của mình và đảm bảo đầu ra chất lượng cao.
Mình nghĩ rằng sẽ hữu ích nếu có một Project hướng dẫn sử dụng DBT. Thiết lập một không gian dành riêng để làm việc với dbt cho các bạn mới bắt đầu trên con đường Data engineer.
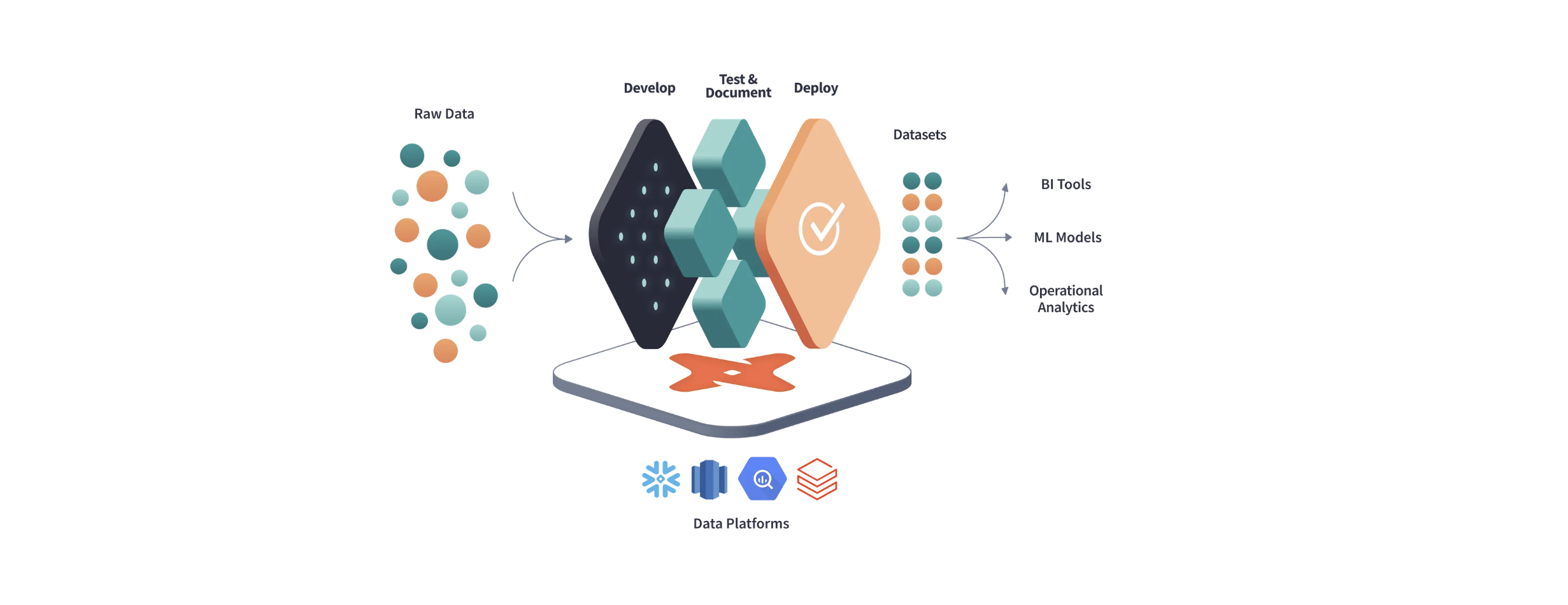
DBT, hay Data Build Tool, là một công cụ mã nguồn mở được sử dụng để biến đổi và kiểm tra dữ liệu trong kho dữ liệu của bạn. Nó cho phép bạn xây dựng, kiểm tra và triển khai mã SQL trong một cách thức có cấu trúc và có thể tái sử dụng.
DBT không phải là một công cụ ETL (Extract, Transform, Load). Thay vào đó, nó tập trung vào phần “Transform” của quy trình ETL, cho phép bạn biến đổi dữ liệu đã được tải lên kho dữ liệu của bạn.
DBT cung cấp một cấu trúc cho mã SQL của bạn, giúp bạn tổ chức mã của mình theo một cách thức có cấu trúc và dễ dàng quản lý. Nó cũng cho phép bạn kiểm tra dữ liệu của mình để đảm bảo rằng nó đáng tin cậy và chính xác.
Dự án đầu tiên của chúng tôi với DBT sẽ hướng dẫn bạn cách thiết lập một không gian làm việc với DBT, cách viết và chạy các biến đổi SQL, và cách kiểm tra dữ liệu của bạn. Chúng tôi hy vọng rằng dự án này sẽ giúp bạn hiểu rõ hơn về cách DBT hoạt động và làm thế nào bạn có thể sử dụng nó để cải thiện quy trình dữ liệu của mình.
Tổng quan về Data trong dự án này
# Set the search path to the "source" schema
cur.execute("SET search_path TO source")
# Create the Customer table
cur.execute("""
CREATE TABLE IF NOT EXISTS customer (
customer_id INTEGER PRIMARY KEY,
customer_name VARCHAR(255),
customer_email VARCHAR(255)
)
""")
# Create the Product table
cur.execute("""
CREATE TABLE IF NOT EXISTS product (
product_id INTEGER PRIMARY KEY,
product_name VARCHAR(255),
price NUMERIC
)
""")
# Create the Order table
cur.execute("""
CREATE TABLE IF NOT EXISTS order_table (
order_id INTEGER PRIMARY KEY,
customer_id INTEGER,
product_id INTEGER,
order_date DATE,
total_amount NUMERIC,
FOREIGN KEY (customer_id) REFERENCES customer (customer_id),
FOREIGN KEY (product_id) REFERENCES product (product_id)
)
""")
# Create the Payment table
cur.execute("""
CREATE TABLE IF NOT EXISTS payment (
payment_id INTEGER PRIMARY KEY,
order_id INTEGER,
payment_date DATE,
payment_amount NUMERIC,
FOREIGN KEY (order_id) REFERENCES order_table (order_id)
)
""")
# Define the data to be inserted into the Customer table
customer_data = [
(1, 'John Doe', 'johndoe@example.com'),
(2, 'Jane Smith', 'janesmith@example.com'),
(3, 'David Johnson', 'davidjohnson@example.com')
]
# Define the data to be inserted into the Order table
order_data = [
(101, 1, 301, '2024-01-15', 150.50),
(102, 2, 302, '2024-02-01', 75.20),
(103, 3, 303, '2024-02-10', 200.00),
(104, 1, 302, '2024-03-05', 100.00)
]
# Define the data to be inserted into the Payment table
payment_data = [
(201, 101, '2024-01-16', 150.50),
(202, 102, '2024-02-02', 75.20),
(203, 103, '2024-02-11', 200.00),
(204, 104, '2024-03-06', 100.00)
]
# Define the data to be inserted into the Product table
product_data = [
(301, 'Laptop', 800),
(302, 'Smartphone', 500),
(303, 'Headphones', 100)
]
try:
# Insert data into the Product table
cur.executemany("INSERT INTO product (product_id, product_name, price) VALUES (%s, %s, %s)", product_data)
# Insert data into the Customer table
cur.executemany("INSERT INTO customer (customer_id, customer_name, customer_email) VALUES (%s, %s, %s)", customer_data)
# Insert data into the Order table
cur.executemany("INSERT INTO order_table (order_id, customer_id, product_id, order_date, total_amount) VALUES (%s, %s, %s, %s, %s)", order_data)
# Insert data into the Payment table
cur.executemany("INSERT INTO payment (payment_id, order_id, payment_date, payment_amount) VALUES (%s, %s, %s, %s)", payment_data)
# Commit the changes to the database
conn.commit()
print("Data inserted successfully!")
except (Exception, psycopg2.DatabaseError) as error:
print("Error inserting data:", error)
finally:
# Close the cursor and connection
if cur:
cur.close()
if conn:
conn.close()
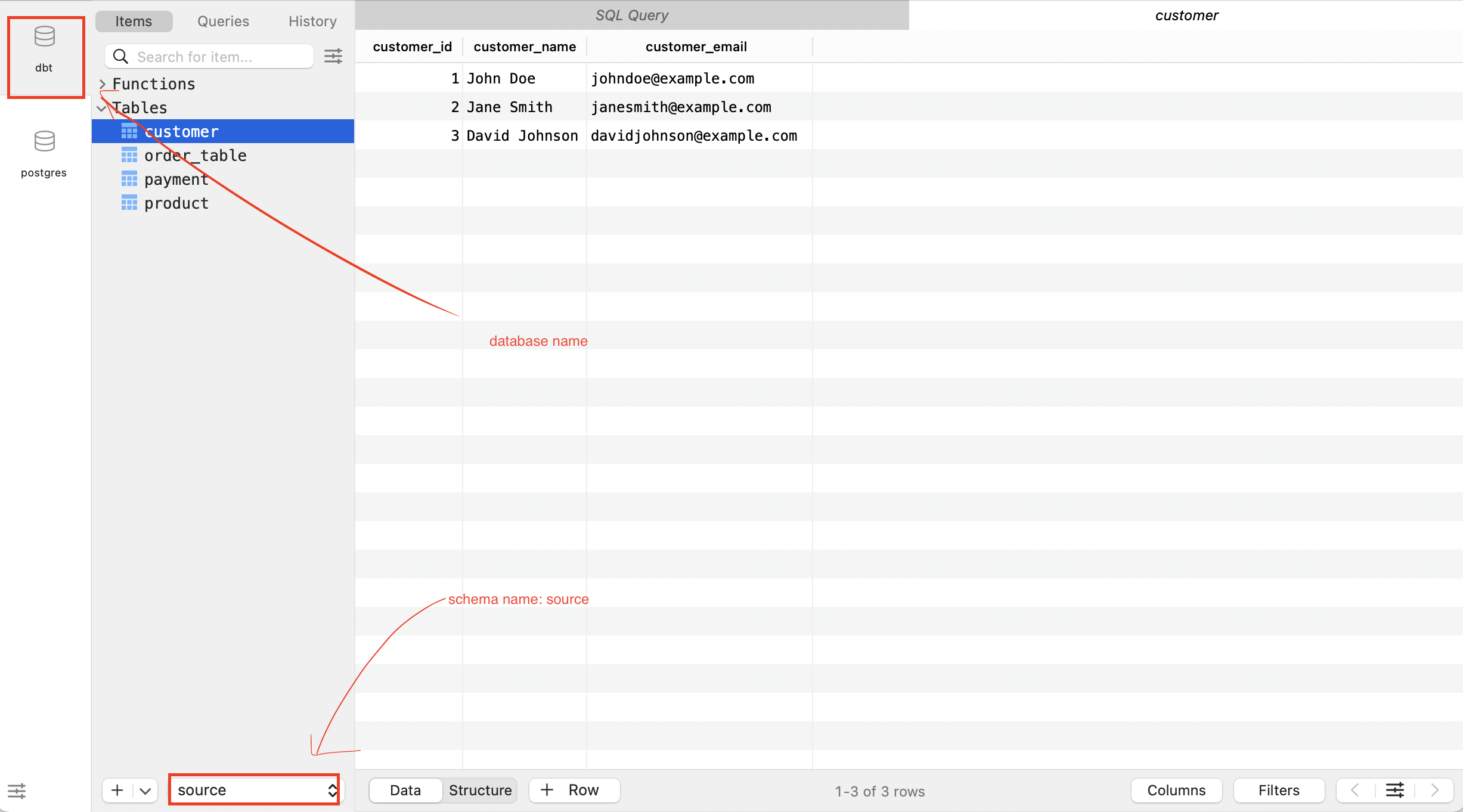
Chúng ta sẽ làm việc tới 4 bảng dữ liệu:
- order
- customer
- product
- payment
Mục tiêu: tổng hợp được thông tin order ứng với khách hàng, thông tin khách hàng, thông tin sản phẩm và khối lượng của mỗi order
Setup Docker cho Postgres
Các bạn pull repository ở đây về, và chuyển tới thư mục
projects/1_data_analytics_postgres_dbt
Các bạn chạy make setup để cài đặt Docker container cho Postgres, cài các Python dependencies cần thiết và tạo data mẫu cho quá trình thực hành.
make setup
# Nội dung của setup
"""
setup:
docker compose up -d
virtualenv env
. env/bin/activate
pip install -r requirements.txt
python3 generate_data.py
"""
Đoạn mã này là một phần của Makefile, một tệp chứa một tập hợp các chỉ thị được sử dụng với công cụ tự động xây dựng make. Dưới đây là giải thích về mỗi dòng:
-
docker compose up -d: Lệnh này khởi động các Docker container ở chế độ detached. Điều này có nghĩa là các Docker container sẽ chạy ở chế độ nền và sẽ không nhận đầu vào từ người dùng. -
virtualenv env: Lệnh này tạo một môi trường ảo mới có tên ‘env’. Môi trường ảo là một công cụ giúp giữ các phụ thuộc cần thiết cho các dự án khác nhau được tách biệt bằng cách tạo các môi trường Python riêng biệt. -
. env/bin/activate: Lệnh này kích hoạt môi trường ảo ‘env’. Một khi môi trường ảo được kích hoạt, trình thông dịch Python và các gói Python được cài đặt trong môi trường ảo sẽ được sử dụng. -
pip install -r requirements.txt: Lệnh này cài đặt các phụ thuộc Python được liệt kê trong tệp ‘requirements.txt’. Tệp ‘requirements.txt’ là một tệp văn bản chứa danh sách các mục cần được cài đặt bằng pip install. -
python3 generate_data.py: Lệnh này chạy script Python ‘generate_data.py’ bằng trình thông dịch Python 3. Script ‘generate_data.py’ được giả định để tạo ra một số dữ liệu cần thiết cho dự án.
Kiểm tra Postgres container đã được khởi tạo
Chạy lệnh sau để xem Container cho Postgres đã tồn tại
docker ps

Kiểm tra dbt đã được cài đặt
Kiểm tra việc cài đặt dbt bằng câu lệnh:
dbt --version
# Kết quả như sau
Core:
- installed: 1.7.10
- latest: 1.7.10 - Up to date!
Plugins:
- postgres: 1.7.10 - Up to date!
Kiểm tra data đã được Insert
Setup DBT profiles và thông tin về Schema, Database và Connection tới Postgres
Các bạn chạy make check để cấu hình thông tin connection tới Database và Test thử connection tới
make check
# Nội dung của check
"""
check:
cp profiles.yml ~/.dbt/profiles.yml
cd $(DIR) && dbt debug
"""
Đoạn code sau đây thực hiện việc sao chép tệp ‘profiles.yml’ vào thư mục ‘.dbt’ trong thư mục home của người dùng. Tệp ‘profiles.yml’ chứa thông tin cấu hình cho dbt, một công cụ dùng để xây dựng và kiểm tra cơ sở dữ liệu.
Sau đó, nó chuyển đến thư mục được chỉ định bởi biến ‘DIR’ và chạy lệnh ‘dbt debug’. Lệnh ‘dbt debug’ kiểm tra xem dbt có thể kết nối đến cơ sở dữ liệu được cấu hình trong tệp ‘profiles.yml’ hay không.
Hãy tìm hiểu xem file profiles.yml
postgres_with_dbt:
outputs:
dev:
dbname: dbt
host: localhost
pass: postgres
port: 5432
schema: 'source'
threads: 1
type: postgres
user: postgres
target: dev
Giải thích về file profiles.yml
File profiles.yml là file cấu hình cho dbt. Nó chứa thông tin về kết nối cơ sở dữ liệu mà dbt sẽ sử dụng. Dưới đây là giải thích về ý nghĩa của từng trường:
-
postgres_with_dbt: Đây là tên của profile. Bạn có thể có nhiều profile trong cùng một fileprofiles.yml. -
outputs: Phần này chứa các cấu hình cho các môi trường khác nhau. Trong trường hợp này, chỉ có một môi trường, đó làdev. -
dev: Đây là tên của môi trường. Bạn có thể có các cấu hình khác nhau cho các môi trường khác nhau, nhưdev,prod,test, v.v. -
dbname: Đây là tên của cơ sở dữ liệu mà dbt sẽ kết nối đến. -
host: Đây là tên máy chủ của máy chủ cơ sở dữ liệu. Trong trường hợp này, máy chủ cơ sở dữ liệu đang chạy trên cùng một máy với dbt, vì vậy tên máy chủ làlocalhost. -
pass: Đây là mật khẩu mà dbt sẽ sử dụng để kết nối đến cơ sở dữ liệu. -
port: Đây là số cổng mà máy chủ cơ sở dữ liệu đang lắng nghe. -
schema: Đây là tên của schema mà dbt sẽ sử dụng trong cơ sở dữ liệu. -
threads: Đây là số lượng luồng mà dbt sẽ sử dụng khi chạy truy vấn. -
type: Đây là loại cơ sở dữ liệu. Trong trường hợp này, cơ sở dữ liệu là một cơ sở dữ liệu PostgreSQL, vì vậy loại làpostgres. -
user: Đây là tên người dùng mà dbt sẽ sử dụng để kết nối đến cơ sở dữ liệu. -
target: Đây là tên của môi trường mà dbt sẽ sử dụng mặc định. Trong trường hợp này, dbt sẽ sử dụng môi trườngdevmặc định.
Kiểm tra kết nối tới Postgres
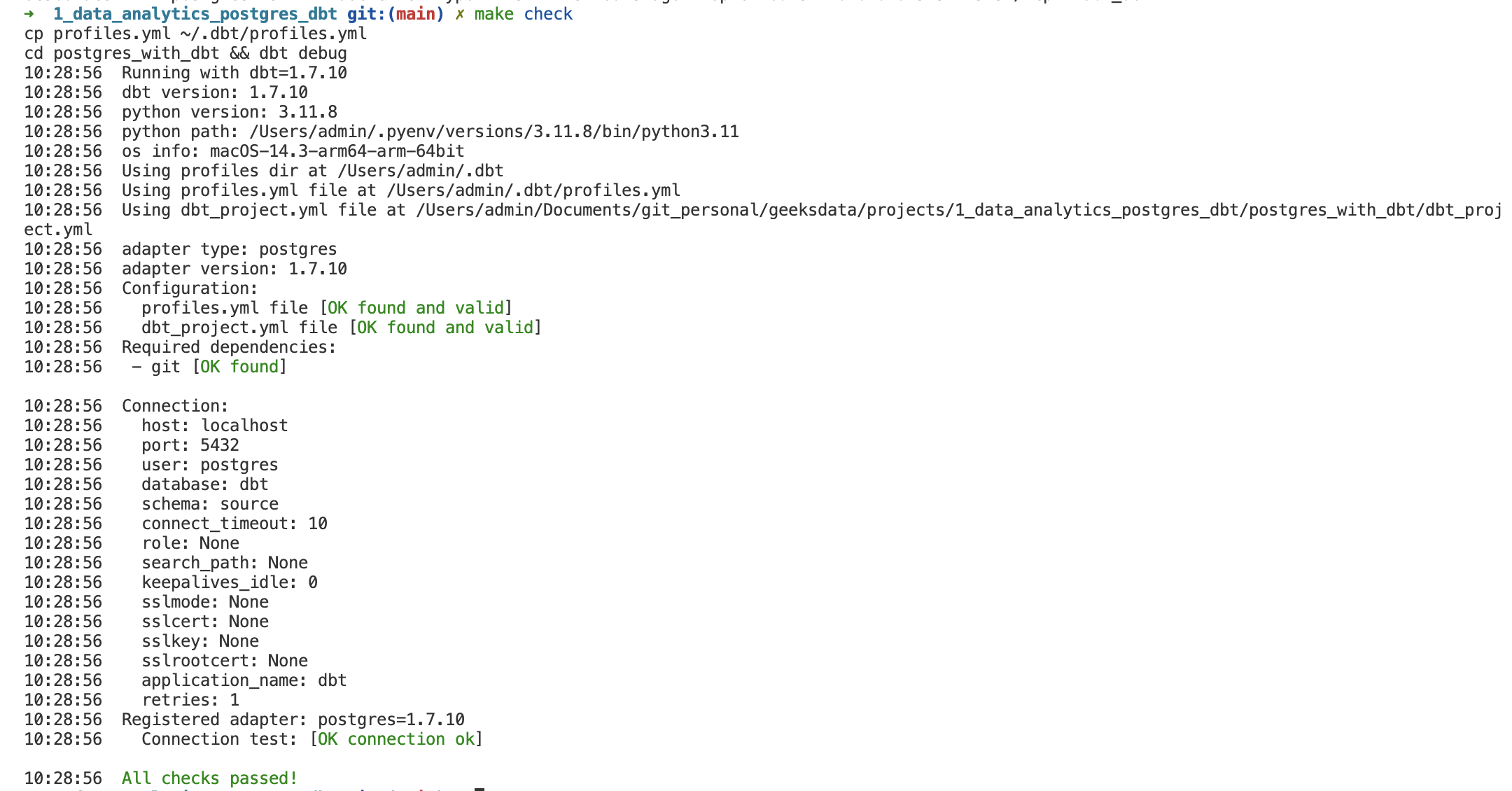 Các bạn thấy all checks pass là xong
Các bạn thấy all checks pass là xong
Run dbt đầu tiên
Bây giờ tới bước xem thành quả của mình rồi
Chạy make run để chạy model
Một số thông tin bạn cần xem trước khi chạy
- Ở trong
postgres_with_dbt/modelssẽ định nghĩa model mà dbt sẽ build ra. Cụ thể trong model của chúng ta:
WITH temp_view AS (
SELECT
o.order_id,
c.customer_name,
p.product_name,
o.order_date,
o.total_amount,
py.payment_date,
py.payment_amount
FROM
o
JOIN c ON o.customer_id = c.customer_id
JOIN p ON o.product_id = p.product_id
JOIN py ON py.order_id = o.order_id
)
SELECT *
FROM temp_view
Đoạn mã này tạo ra một view tạm thời có tên là temp_view. View này được tạo ra bằng cách chọn một số trường từ nhiều bảng trong cơ sở dữ liệu. Các bảng này là order_table, customer, product, và payment. Các bảng này được kết hợp lại với nhau dựa trên một số điều kiện để tạo ra một cái nhìn toàn diện về dữ liệu.
Dưới đây là phân tích chi tiết câu truy vấn SQL:
-
SELECT o.order_id, c.customer_name, p.product_name, o.order_date, o.total_amount, py.payment_date, py.payment_amount: Dòng này chọn các trường sẽ được bao gồm trong view. Các trường này làorder_id,customer_name,product_name,order_date,total_amount,payment_date, vàpayment_amount. -
FROM o: Dòng này chỉ địnhorder_tablelà bảng chính cho câu truy vấn.osau tên bảng là bí danh choorder_table. -
JOIN c ON o.customer_id = c.customer_id: Dòng này kết hợp bảngcustomervớiorder_tablevới điều kiệncustomer_idtrong cả hai bảng đều bằng nhau.clà bí danh chocustomer. -
JOIN p ON o.product_id = p.product_id: Dòng này kết hợp bảngproductvớiorder_tablevới điều kiệnproduct_idtrong cả hai bảng đều bằng nhau.plà bí danh choproduct. -
JOIN py ON py.order_id = o.order_id: Dòng này kết hợp bảngpaymentvớiorder_tablevới điều kiệnorder_idtrong cả hai bảng đều bằng nhau.pylà bí danh chopayment.
Cuối cùng, SELECT * FROM temp_view được sử dụng để chọn tất cả các trường từ temp_view vừa được tạo.
Định nghĩa source schema trong dbt
version: 2
sources:
- name: source
database: dbt
schema: source
tables:
- name: customer
- name: order_table
- name: payment
- name: product
-
version: 2: Dòng này chỉ định phiên bản của tệp cấu hình dbt. Phiên bản hiện tại là 2. -
sources: Đây là danh sách các nguồn mà dbt có thể lấy dữ liệu từ. Mỗi nguồn được định nghĩa bởi một tập hợp các thuộc tính. -
- name: source: Dòng này định nghĩa một nguồn có tên làsource. Đây là định danh bạn sẽ sử dụng khi tham chiếu đến nguồn này trong các mô hình dbt của bạn. -
database: dbt: Dòng này chỉ định cơ sở dữ liệu mà nguồnsourceđang nằm trong. Trong trường hợp này, cơ sở dữ liệu làdbt. -
schema: source: Dòng này chỉ định lược đồ mà nguồnsourceđang nằm trong. Trong trường hợp này, lược đồ làsource. -
tables: Đây là danh sách các bảng trong nguồnsource. Mỗi bảng được định nghĩa bởi một tập hợp các thuộc tính. -
- name: customer: Dòng này định nghĩa một bảng có tên làcustomertrong nguồnsource. -
- name: order_table: Dòng này định nghĩa một bảng có tên làorder_tabletrong nguồnsource. -
- name: payment: Dòng này định nghĩa một bảng có tên làpaymenttrong nguồnsource. -
- name: product: Dòng này định nghĩa một bảng có tên làproducttrong nguồnsource.
Kết quả (mình sử dụng TablePlus để View)
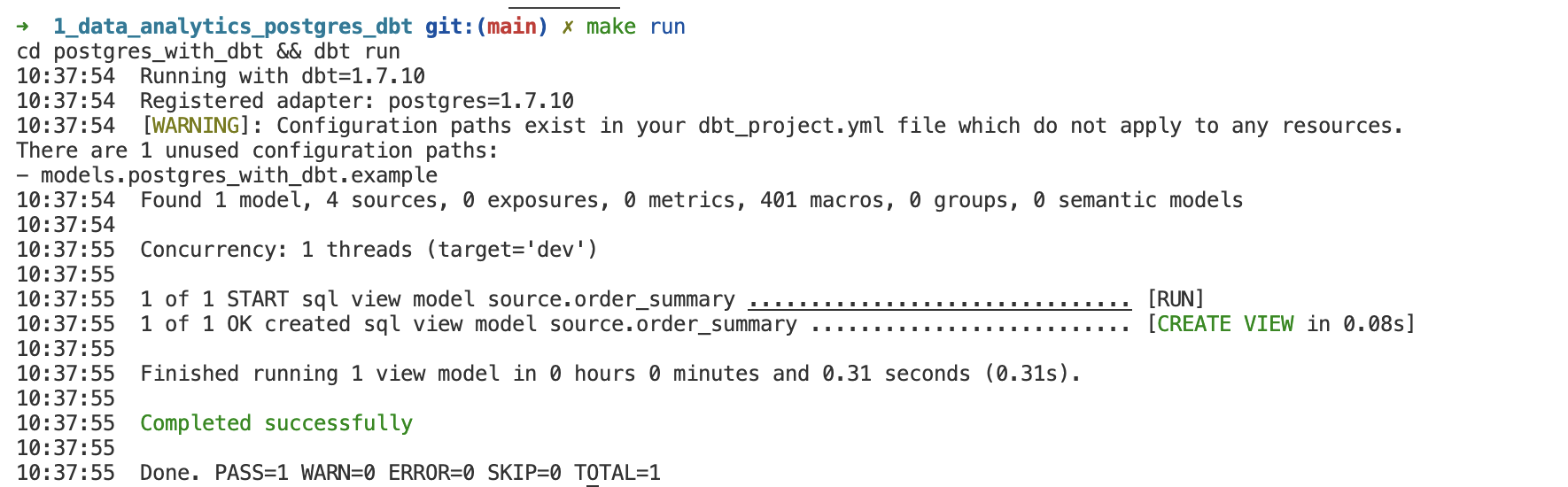
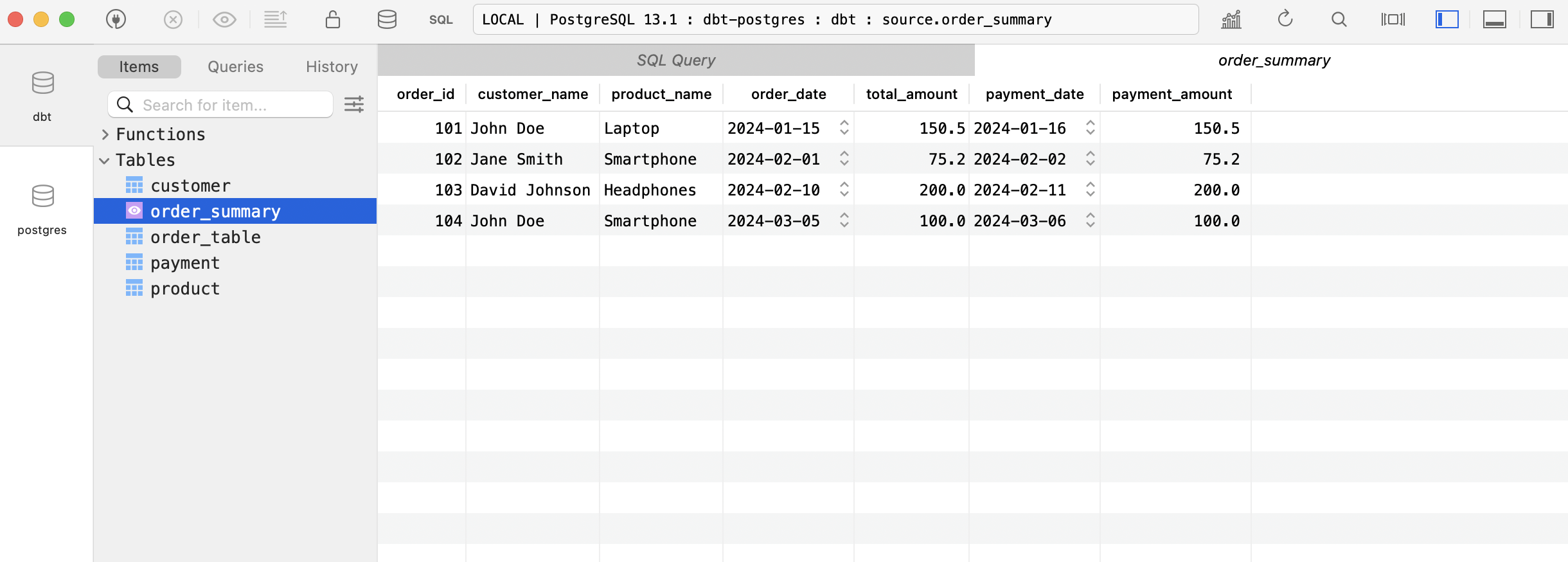
Generate document và xem Lineage trên Web bằng DBT gen docs
Chạy make serve-dbt để xem thông tin về Job chạy, thông tin table và đường đi (lineage) của nó:
serve-dbt:
cd postgres_with_dbt && dbt docs generate && dbt docs serve --port 8001
Hiển thị khá chi tiết thông tin về source, bảng và cột
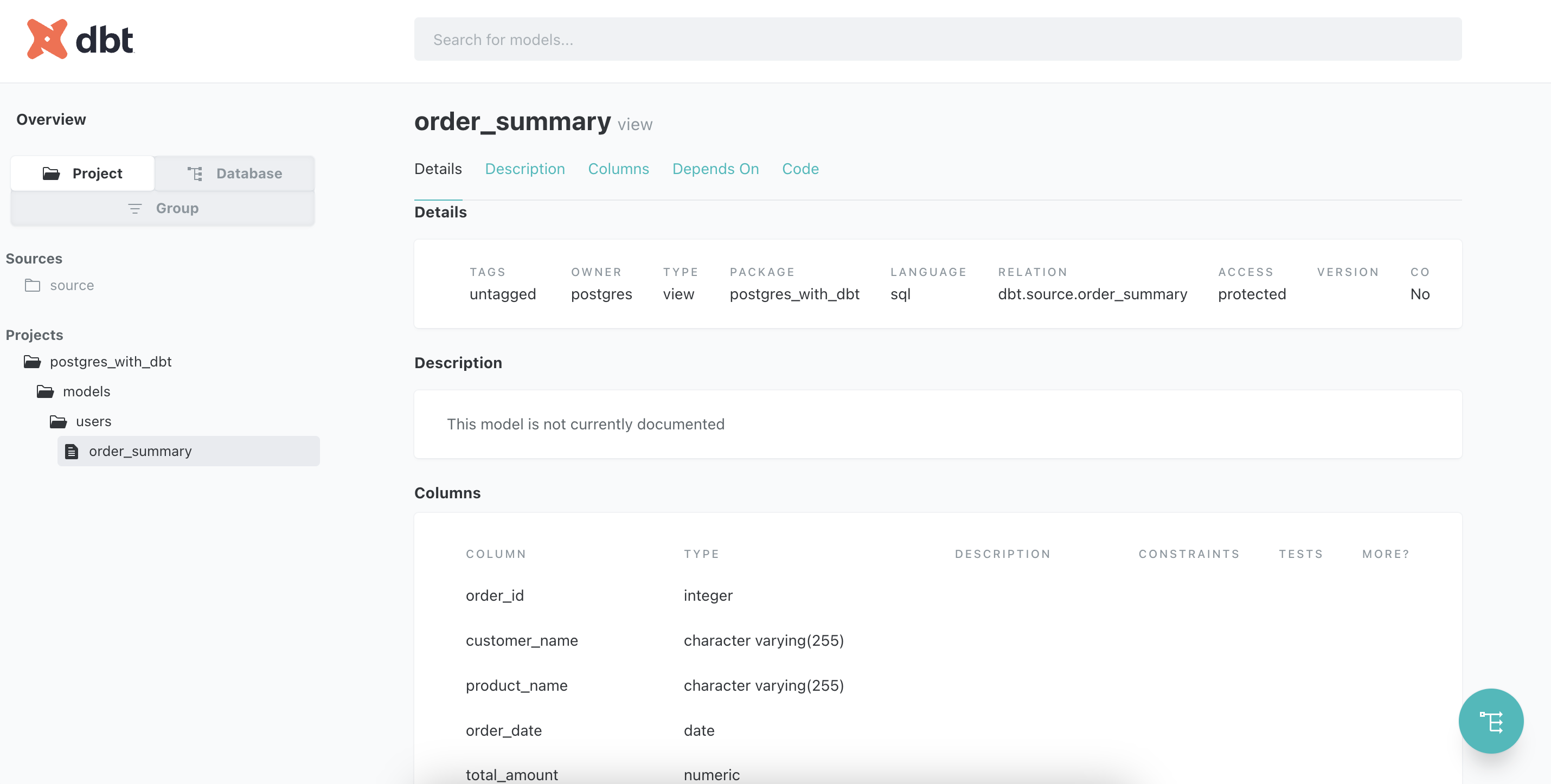
Đây là thông tin về code:
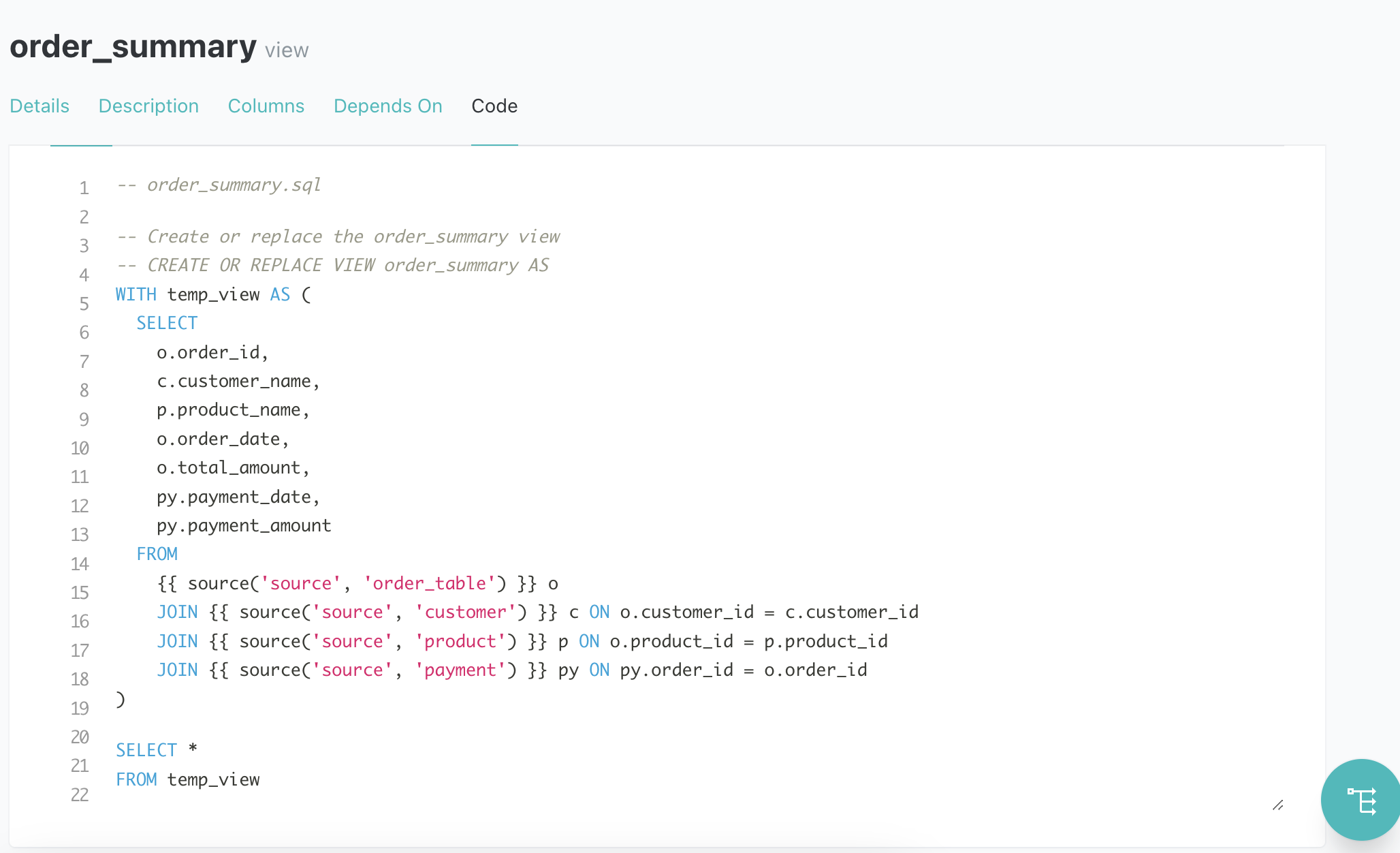
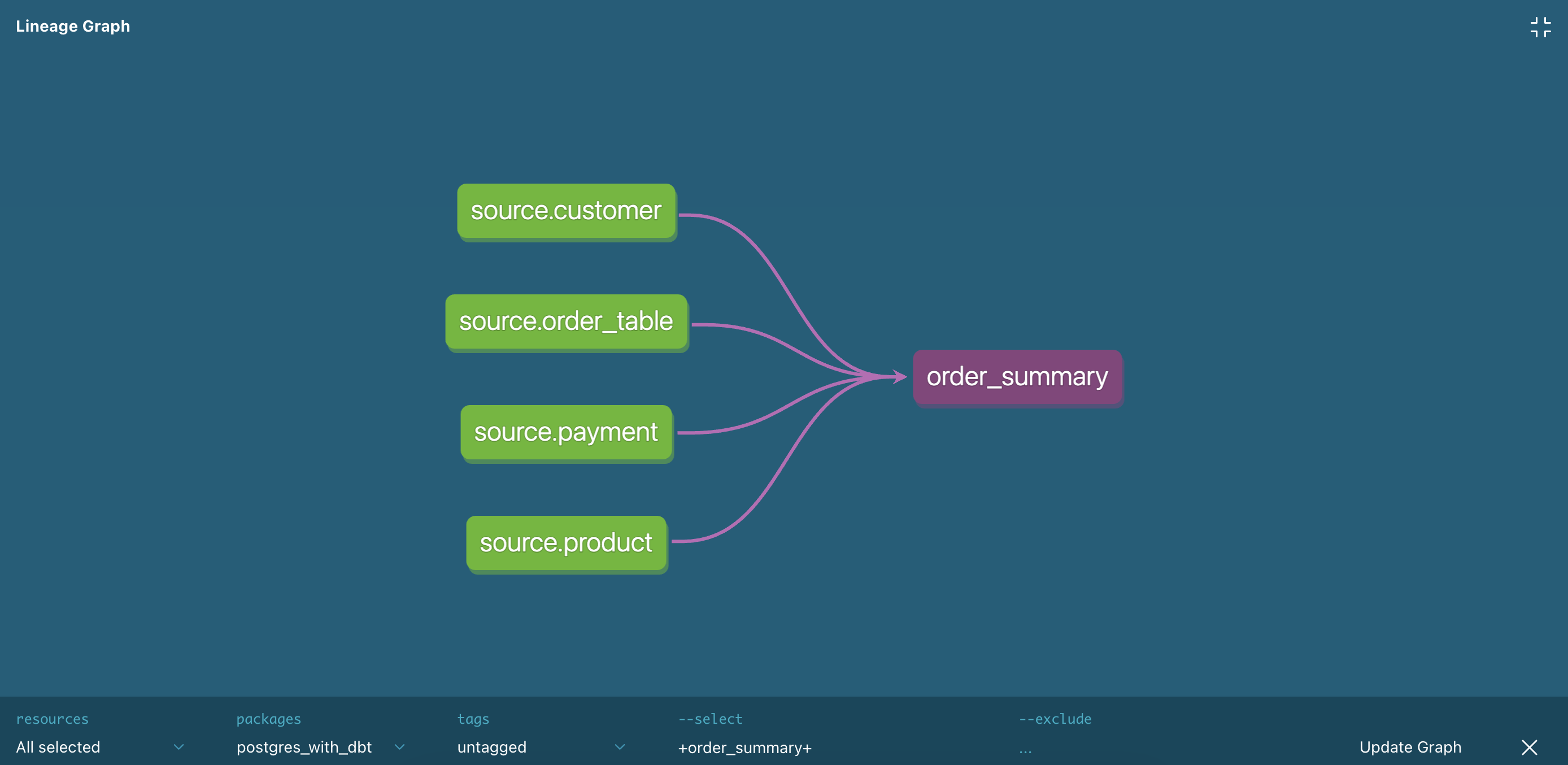
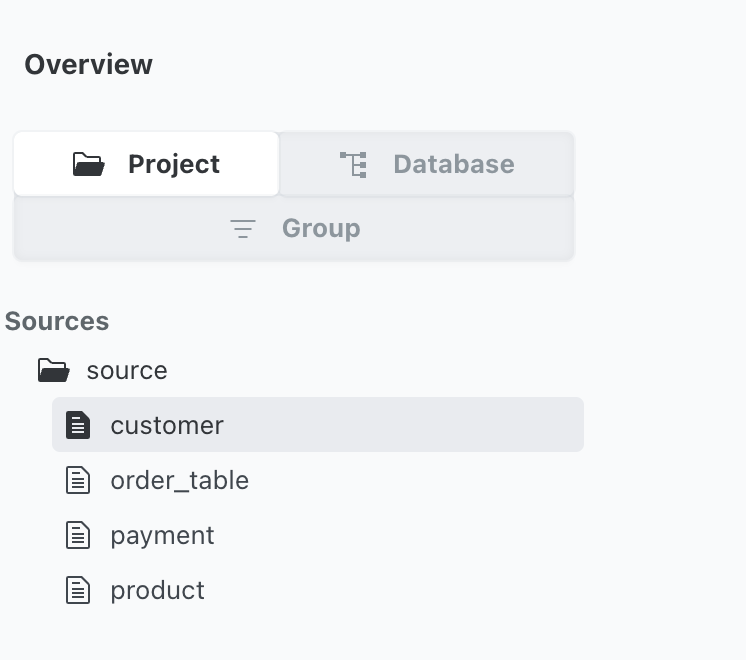
Các bảng phụ thuộc:
Cùng xem lại bảng kết quả:

Kết luận
Qua dự án này, chúng ta đã tìm hiểu và thực hành với dbt, một công cụ rất mạnh mẽ trong việc xây dựng và quản lý data warehouse.
Chúng ta đã học cách cấu hình dbt, định nghĩa nguồn dữ liệu, tạo và kiểm tra các mô hình dbt. Đặc biệt, chúng ta đã thấy được sức mạnh của dbt trong việc tự động hóa quá trình ETL, giúp tiết kiệm thời gian và công sức đáng kể.
Ngoài ra, chúng ta cũng đã thực hành việc tạo document và xem lineage trên web bằng dbt gen docs, giúp chúng ta dễ dàng theo dõi và quản lý dữ liệu.
Hy vọng rằng, qua dự án này, bạn đã nắm bắt được kiến thức cơ bản về dbt và có thể áp dụng vào công việc thực tế của mình. Hãy tiếp tục khám phá và học hỏi để trở thành một data engineer giỏi nhé!